01-Beginning
ADT与DS
抽象数据类型(Abstract Data Type,ADT)是计算机科学中具有类似行为的特定类别的数据结构的数学模型;或者具有类似语义的一种或多种程序设计语言的数据类型。抽象数据类型 = 数据模型 + 定义在该模型上的一组操作。
数据结构(Data Structure)是计算机存储、组织数据的方式.数据结构 = 基于某种特定语言,实现ADT的一整套算法。
对比:
抽象数据类型ADT 数据结构DS 抽象定义 具体实现 一种定义 多种实现 外部的逻辑特性 内部的表示和实现 不考虑时间复杂度 与复杂度密切相关 只考虑操作和语义 需要完整的算法实现 不涉及数据的存储方式 要考虑数据的具体存储机制 通俗易懂的例子:汽车驾驶员关心汽车的性能和驾驶表现;汽车制作者负责实现汽车的相应功能,二者通过汽车使用手册(说明书,ADT)来达成某种协议。
另例:
int n表示指定n属于int数据类型,其具有了int类型的某些特点,并支持相应的操作方法。但是,我们不用关心任务是如何完成的,而是关心能做什么。所以,我们需要将某些东西隐藏起来,不必详细说明实现过程。int float char Vector等都是抽象数据类型。抽象:不需详细说明实现过程的泛化操作称为抽象。即“抽取了过程的本质,而隐藏了实现的细节。
渐进分析
渐进符号
基础内容
Bachmann-Landau notation, also known as "Big-Oh" notation, abstracts away all constants in asymptotic analysis.
让
if such that for all . if such that for all . if both and hold.
对于Big-O和Big-Omega的严格版本,定义如下:
if for every constant , there exists an integer such that for all . if for every constant , there exists an integer such that for all .
此外,我们还可以这样表示:
if for some constant which is independent of n.
if for some constant which is independent of n.
if both and hold. (i.e. if for some constant which is independent of n.)
if .
if .
注意:可以小写字母的符号推导到大写字母的符号,但是不能从某一个渐进符号的大写推出他的小写形式。
令
, ,则有: 令
即可。但是,不能说 或 。
增长速度
| Function | Type of Growth |
|---|---|
| Constant Growth | |
| Iterative Logarithmic Growth | |
| Twice Iterative Logarithmic Growth | |
| Logarithmic Growth | |
| Polylogarithmic Growth | |
| Sublinear Growth | |
| Linear Growth | |
| Logarithmic-Linear Growth | |
| Polylogarithmic-Linear Growth | |
| Polylogarithmic-Polynomial Growth | |
| Quadratic Growth | |
| Cubic Growth | |
| Polynomial growth (General Situation) | |
| Quasi-Polynomial Growth | |
| Exponential Growth | |
| Factorial Growth | |
| Super-Exponential Growth |
计算技巧
For any
, we have . Striling Formula:
. - For example, using Stirling Formula, we can prove that
.
- For example, using Stirling Formula, we can prove that
Addition Rule:
- If
and , then ; - If
and , then .
- If
Composition Rule:
- If
and , then ; - If
and , then .
- If
L'Hôpital's Rule: Suppose
and are both differentiable functions which satisfy L'Hôpital's Rule prerequisties, then - If
, then ; - Otherwise,
.
注意:这里不能使用
. - If
Intergal Theorem: Let
be an increasing function or decreasing Riemann-integrable function over the interval , then if
is a decreasing function. Moreover, if is an increasing function, the same is true, provided that .
例题
- 判断
是否为 :
Question 1: Prove that
is . Answer 1:
. Let . So statement is true. Q.E.D.
- 判断
和 的时间复杂度关系(注意,不是所有的方程都能在渐进的意义下进行比较,如 ):
Question 2: Compute
to find the relationship: Answer 2:
- if it limits to 0:
; - if it limits to
: ; - if it limits to non-zero values:
(i.e. A(n) and B(n) has the same growth rate.); - if it limits oscillationally, they are no relationship.
Question 3: Prove that
, where . which is to say,
is . grows more than B(n).
参考资料
递归式求解——代入法、递归树与主定理
递归式求解——代入法、递归树与主定理 - 知乎 (zhihu.com)
Master theorem (analysis of algorithms) - Wikipedia
从分治法到递归式
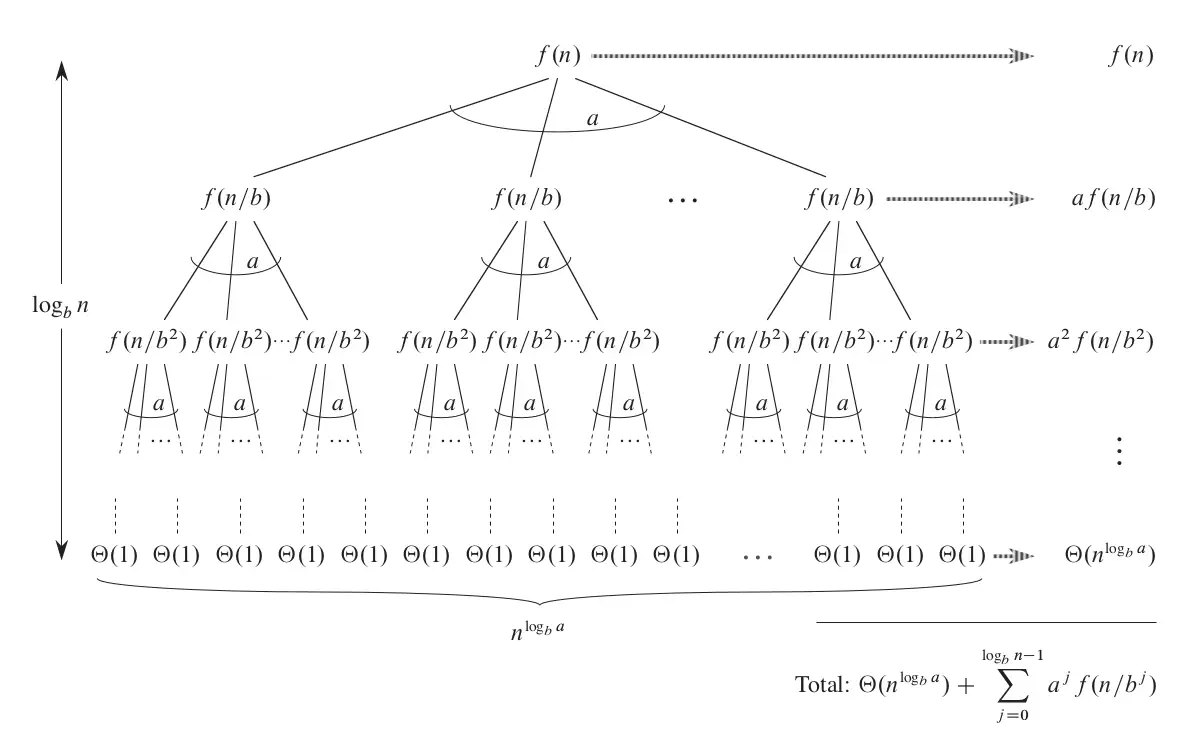
所谓分治法,就是把大问题分解成小问题,再把小问题的解合并成原问题的解。递归式则是用数学语言对这一过程的时间代价建模。如MergeSort的递推式:
递归式的右侧通常由两部分组成,第一部分是分解后子问题的总代价,第二部分是分解和合并子问题的总代价。第一部分仍然是T的函数,第二部分则是实际的渐进复杂度。
以下有三种方法来求解递归式:代入法、递归树和主定理。
代入法
- 我们需要先猜出解的形式,然后用数学归纳法证明该猜测是正确的。
- 实例:假设猜测MergeSort的T解是
然后猜测MergeSort , 若两者均正确,则MergeSort的T解为 . - 代入法依赖于准确的猜测。
递归树
- 把递归式逐层展开,直接就能得到一个树形结构。
- 实例:
. 具体流程见网页链接。每层数据规模缩小为之前的四分之一,直到叶子结点数据规模为1,因此总层数为 。右侧计算了每层所有结点的总代价:单个结点的代价乘以该层结点数量。最后一层单个结点的代价为常数,结点数量 ,记作 。然后对几何级数求和(放缩、舍去低阶项)。 - 有些情况下,利用递归树计算精确的解会稍有困难,但不妨碍我们做出一个合理的猜测,然后进一步用代入法验证该猜测。
主方法
代入法和递归树法各有缺点,前者需要一个准确的猜测,后者需要画出递归树并推导结果。而大部分递归式解的形式都是一样的。我们也许可以通过对递归式分类,按照某种规则直接写出最终的解。
若分治法每一次都均分数据时,递归式具有如下一般的形式:
这里,a是一个正整数,表示每次分治,问题被分解为a个子问题;
b 是一个大于1的整数,表示每次分治,问题规模缩小为之前的
. f(n)是渐进正函数,表示分解和合并的代价。
用递归树找统一解,Total为所有节点的总代价:
下面有三种情况,按照两个和项的大小进行分类,即比较
- 若
渐进小于 .,即认为 成立时,有 为 .
If
is , then is .
- 若
和 相等 ,则 .
If
is , then is .
- 若
渐进大于 ,且对于 <1和所有足够大的n有 , 则有 .
If
is , then T(n) is , provided a for some .
实例:
必须注意,主定理第三条要检查其是否满足附加条件。并非所有满足上面形式的式子都可以使用主定理来进行判定。如
对于该式,有
,此时 。显然, 渐进大于 ,应考虑主定理的第三种情况。将其带入附加条件,得 当
时,该式恒成立。但附加条件要求 ,因此该式不能使用主方法的第三种情况。结果为 .
令解:带入方法2可求解。
特别内容
- 对于任意一个符合主定理格式的递归式,如果它满足情况三中的正则条件,那么它一定满足
, 而反过来不可推出。 - 另一个例子:求解递推方程
. 这个递归树的树叶不在同一层上面。此时,应从最坏的情况出发,考虑最长的路径。那么这个递归树一共有 层。(2n/3一侧的路径最长,每走一步,问题规模会变成原来的2/3.)而每一层节点的数值之和为O(n),从而有: .
Wikipedia上的主定理——Generic Form
The master theorem always yields asymptotically tight bounds to recurrences from divide and conquer algorithms that partition an input into smaller subproblems of equal sizes, solve the subproblems recursively, and then combine the subproblem solutions to give a solution to the original problem. The time for such an algorithm can be expressed by adding the work that they perform at the top level of their recursion (to divide the problems into subproblems and then combine the subproblem solutions) together with the time made in the recursive calls of the algorithm. If
denotes the total time for the algorithm on an input of size and denotes the amount of time taken at the top level of the recurrence then the time can be expressed by a recurrence relation that takes the form: Here
is the size of an input problem, is the number of subproblems in the recursion, and is the factor by which the subproblem size is reduced in each recursive call (b>1). Crucially, and must not depend on . The theorem below also assumes that, as a base case for the recurrence, when is less than some bound , the smallest input size that will lead to a recursive call. Recurrences of this form often satisfy one of the three following regimes, based on how the work to split/recombine the problem
relates to the critical exponent . Case 1:
Description: Work to split/recombine a problem is dwarfed by subproblems. (I.e. the recursion tree is leaf-heavy.)
Condition on
in relation to , i.e. : When where $ c<c_{crit}$. (upper-bounded by a lesser exponent polynomial) Master Theorem bound: then
. (The splitting term does not appear; the recursive tree structure dominates.) Notational examples: If
and , then . 描述:拆分/重组问题的工作与子问题相形见绌。(即递归树的叶子过多)
和 的关系:当 时,其中 。(上界为小指数多项式) 主定理的约束条件:
。(递归树占主导地位,而未出现拆分项。)
Case 2:
Description: Work to split/recombine a problem is comparable to subproblems.
Condition on
in relation to , i.e. : When for a (rangebound by the critical-exponent polynomial, times zero or more optional ) Master Theorem bound: then
(The bound is the splitting term, where the log is augmented by a single power.) Notational examples: If
and , then ; If and , then . 描述:拆分/重组问题的工作与子问题相当。
和 的关系:当 时,其中 。(界被 所限,乘以零或可选的 ) 主定理的约束条件:
。(界值为拆分项,对数的次数增加1。)
Case 3:
Description: Work to split/recombine a problem dominates subproblems. (I.e. the recursion tree is root-heavy.)
Condition on
in relation to , i.e. : When where . (lower-bounded by a greater exponent polynomial) Master Theorem bound: this doesn't necessarily yield anything. Furthermore, if
for some constant and sufficiently large (often called the regularity condition) then the total is dominated by the splitting term : . Notational examples: If
and and the regularity condition holds, then . 描述:拆分/重组问题的工作远胜于子问题。(即递归树的根过多)
和 的关系:当 时,其中 。(下界为大指数多项式) 主定理的约束条件:这不一定有结果。若
和一个很大的 (规则性条件),有 ,则结果由拆分项 主导, 。
A useful extension of Case 2 handles all values of
| Case | Condition on | Master Theorem bound | Notational examples |
|---|---|---|---|
| 2a | When | ... then | If |
| 2b | When | ... then | If |
| 2c | When | ... then | If |
摊还分析
摊还分析(Amortized Analysis)是一种确定数据结构操作成本的高级策略,它可以找出在一系列操作中,平均每个操作的时间复杂度。摊还分析并不关注每个操作的实际成本,而是关注操作序列的平均成本。参见数据结构时间复杂度的摊还分析(均摊法)之一:基础
摊还分析有三种常见的方法:
聚集分析(Aggregate Analysis):这种方法将一系列操作的总成本分摊到每个操作上。例如,如果我们有一个可以在O(1)时间内完成插入的数据结构,但是每10次插入需要花费O(n)的时间来重新整理,那么聚集分析会将这个O(n)的成本分摊到这10次插入上,得出平均每次插入的成本是O(1)。
记账法(Accounting Method):这种方法通过给便宜的操作“存款”,然后在昂贵的操作时“取款”来进行分析。便宜的操作存款的额度会超过它们的实际成本,这个额外的成本就是为了在后面昂贵的操作时使用。
势能法(Potential Method):这种方法将数据结构看作是一个物理系统,定义一个“势能”函数来度量系统的“能量”。便宜的操作会增加系统的势能,昂贵的操作会消耗势能。通过势能的变化,我们可以计算出操作的摊还成本。
例如,动态数组(Vector)等可以使用聚合分析;二叉堆的插入操作和栈的入栈、出栈和遍历出栈可以使用记账法;斐波那契堆删除的最小元素操作可以使用势能法。