向量索引
上一章介绍 Indexing 中提到,要将这些 embedding 后的向量存储在专门的数据库中,构建索引结构(如倒排索引或向量索引),以便快速检索。这就需要用到向量数据库了。向量数据库是一种专门用于存储、索引、查询和检索高维向量数据的数据库系统。它特别适合处理非结构化数据,如图像、音频和文本,能够实现传统数据库难以完成的高级分析和相似性搜索,具备高效存储和处理高维向量数据的能力。
如何选择向量数据库?
常见的向量数据库包含 Milvus、Elasticsearch、Faiss、Chroma 等,选择时可以考虑的因素有:
数据规模和速度需求:考虑你的数据量大小以及查询速度的要求。一些向量数据库在处理大规模数据时更加出色,而另一些在低延迟查询中表现更好。
持久性和可靠性:根据你的应用场景,确定你是否需要数据的高可用性、备份和故障转移功能。
易用性和社区支持:考虑向量数据库的学习曲线、文档的完整性以及社区的活跃度。
成本:考虑总体拥有成本,包括许可、硬件、运营和维护成本。
特性:考虑你是否需要特定的功能,例如多模态搜索等。
安全性:确保向量数据库符合你的安全和合规要求。
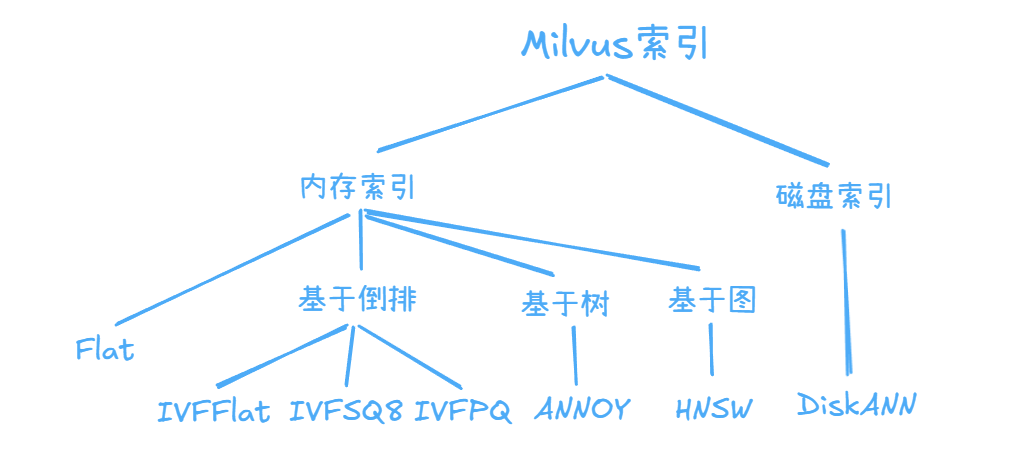
接下来深入探讨 Milvus 所支持的几种主要向量索引的原理:
ANNS
在处理高维数据时,最近邻搜索(NNS, Nearest Neighbor Search)是一个常见且重要的任务。NNS 旨在通过给定的查询向量,快速找到数据集中最相似的若干个向量。这在图像检索、推荐系统、语音识别等应用中具有广泛的需求。然而,随着数据规模的增大,精确的最近邻检索通常会变得非常耗时和资源密集。因此,近似最近邻搜索(ANNS, Approximate Nearest Neighbor Search)应运而生。
ANNS 的核心思想是在可接受的精度范围内,牺牲部分准确性,换取更高的检索效率。相比于精确检索,ANNS 只需要找到目标向量的近似邻居,而不是完全精确的邻居,从而在大规模数据集上大幅提升查询速度。Milvus 支持的向量索引类型大多采用 ANNS 算法,常见的索引类型的划分如下图所示:
FLAT
这是最简单的索引方式,进行暴力搜索(brute-force),可以保证精确度,但效率低,尤其在数据量大时。
适合场景:在小型、百万级数据集上寻求完全精确的搜索结果。
IVF_FLAT
IVF_FLAT 是一种基于倒排的索引方法,广泛用于在大规模数据集上实现高效的近似最近邻搜索。它适用于在精度和查询速度之间寻求平衡的场景。IVF_FLAT 本身并没有进行量化操作,因此在精度和存储开销上相对保守,但能够提供较快的搜索速度。
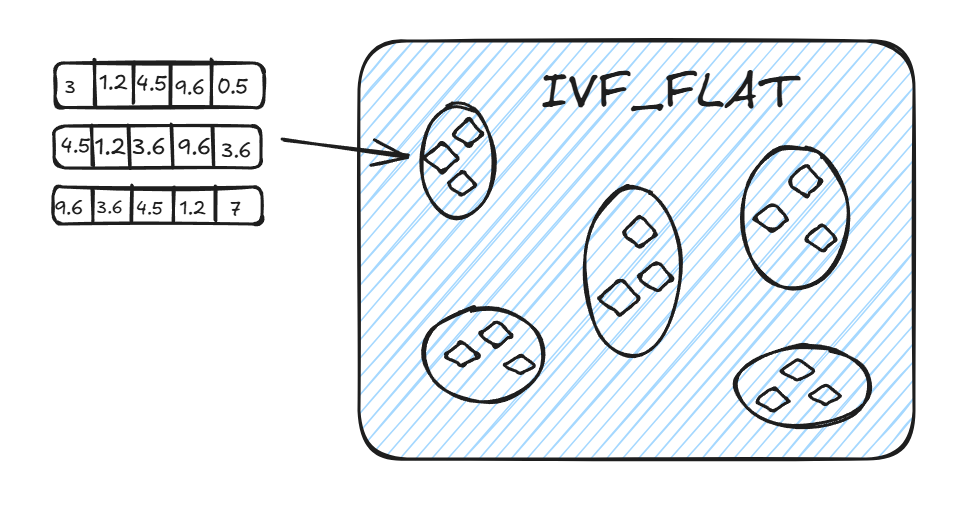
核心原理
聚类:IVF_FLAT 通过聚类算法(如 k-means)将高维空间中的向量划分为多个子空间(簇)。每个簇包含一组相似的向量,并且每个簇会有一个代表向量,通常是簇的中心点。
倒排索引:为每个簇创建倒排索引。每个向量会被映射到它所属的簇,这样在查询时,系统只需关注与查询向量相似的簇,而不需要搜索整个高维空间,从而显著降低搜索的时间复杂度。
查询处理:
查询时,IVF_FLAT 首先将查询向量分配到距离最近的簇中心(即子空间)。
然后在该簇内执行精确的线性搜索,从而查找与查询向量相似的向量。
为了优化查询,IVF_FLAT 使用一个参数
nprobe来控制搜索的簇数。nprobe控制搜索时考虑的簇的数量,从而平衡查询精度和查询速度:增大
nprobe可以搜索更多簇,返回更多候选向量,提高结果的精确度,但查询时间也会增加。减少
nprobe可以缩小搜索范围,降低计算时间,查询速度更快,但可能会牺牲一些精度。
降低搜索成本:由于 IVF_FLAT 通过划分子空间来限制搜索范围,它能够显著减少传统线性搜索所带来的高维数据中的计算开销,从而提高查询效率。与传统的暴力搜索方法相比,IVF_FLAT 的时间复杂度大大降低,尤其适合在大规模数据集上使用。
适用场景
IVF_FLAT 适用于需要平衡精度和查询速度的场景,尤其是在大规模、高维数据集上,可以有效减少查询时间。它适合那些要求较高精度但能容忍一定查询延迟的应用。
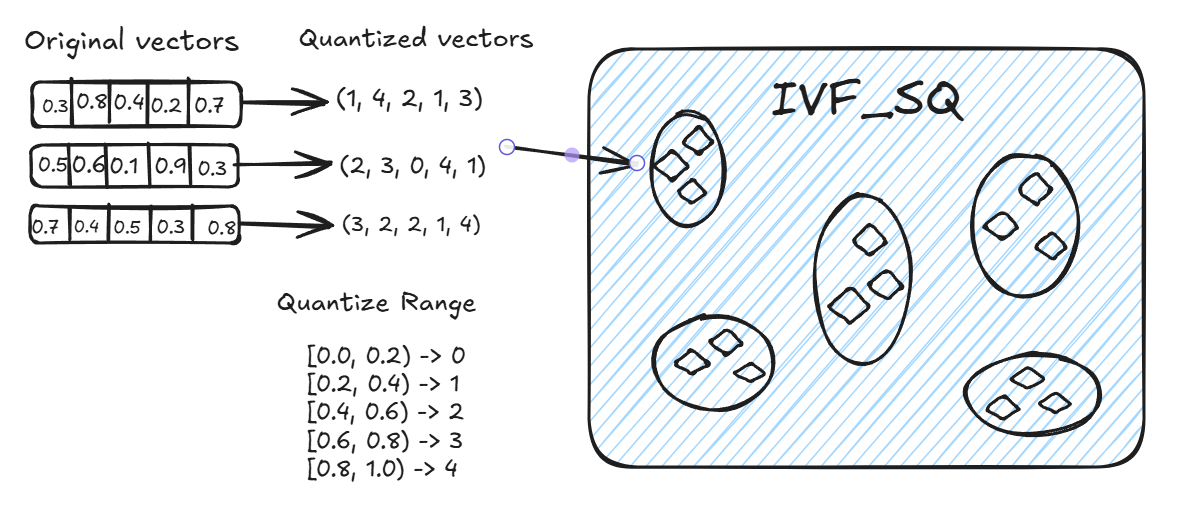
IVF_SQ8
IVF_SQ8 是在 IVF_FLAT 基础上增加了量化步骤的一种索引方法,其核心思想与 IVF_FLAT 类似,但通过量化技术将存储和计算资源的消耗大大降低,尤其在磁盘、内存、CPU 和 GPU 资源的使用上节省了 70%-75%。IVF_SQ8 通过标量量化(Scalar Quantization)将每个维度的 4 字节浮点数表示压缩为 1 字节整数表示。
核心原理
标量量化:IVF_SQ8 通过标量量化将每个向量的每个维度从 4 字节(通常是浮点数)压缩为 1 字节。量化的过程是将原始的浮点数值映射到一个较小的整数范围。例如,假设一个维度的原始值范围是 [0.0, 1.0],通过量化后,该维度的数值会被压缩为整数值,这样可以显著节省存储空间并加速计算。
Quantized Vectors:量化后的向量使用整数(如 uint8)来表示每个维度的值。通过量化,向量的存储空间大大减少,同时查询时计算量也降低。量化后的整数表示会根据原始值的分布划分为若干个区间。
倒排索引与聚类:与 IVF_FLAT 类似,IVF_SQ8 使用聚类算法(如 k-means)将高维空间中的向量划分为多个簇。每个簇内的向量都通过量化后的表示存储和检索。查询时,系统会将查询向量分配到与其最接近的簇中心,然后在该簇内执行快速的线性搜索。
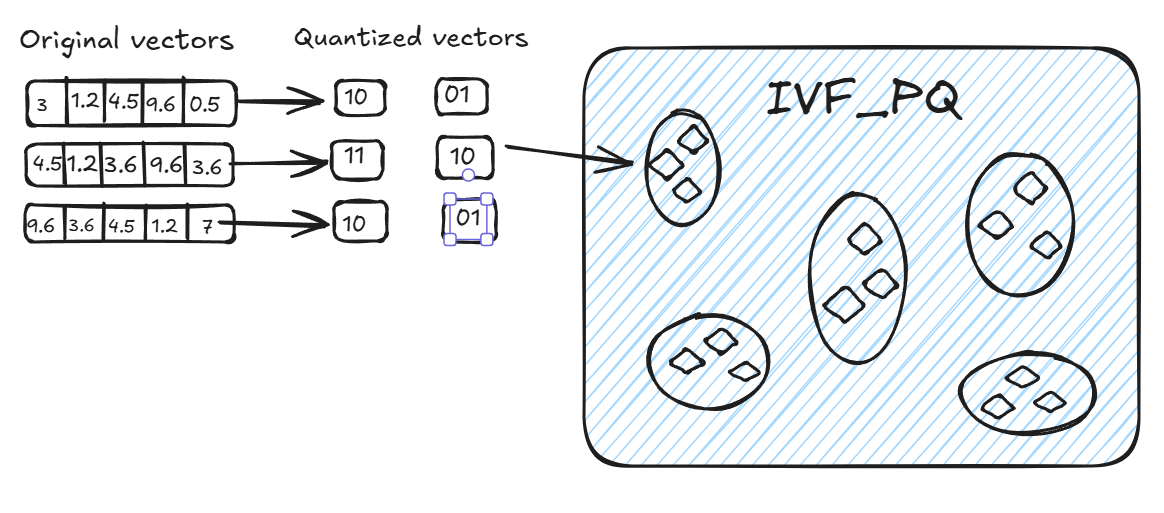
IVF_PQ
IVF_PQ 是一种结合了倒排文件和乘积量化(Product Quantization, PQ)的高效索引方法,旨在加速大规模高维数据集的检索过程。它主要用于高维向量的近似最近邻搜索,通过将向量空间划分为更小的子空间并进行量化,显著降低了存储开销和计算复杂度。
- 倒排文件
倒排文件是一种高效的索引结构,用于存储和检索向量。在 IVF_PQ 中,数据集中的每个向量被分配到一个或多个倒排表中,每个表包含了对应向量的标识符。查询时,我们首先在倒排文件中找到候选的向量集合,从而大大减少了搜索空间。倒排文件特别适合于高维空间,因为它允许我们仅搜索与查询向量相似的部分数据,而不是遍历整个数据集。
- 乘积量化(PQ)
乘积量化是一种将高维向量压缩为低维表示的技术。它通过将向量划分为多个子空间,并对每个子空间进行独立的量化,生成一个代码本(codebook)。这样,原始的高维向量可以由多个子空间的量化表示组合而成,从而降低存储需求并加速检索。
在 IVF_PQ 中,乘积量化应用于 IVF 的聚类过程。每个簇的中心点会被进一步量化,原始的查询向量和数据向量在计算距离时,不是直接与每个簇中心进行计算,而是与每个子空间的量化中心进行计算。这种方法不仅降低了存储开销,还减少了计算距离时的运算量。
- IVF_PQ 的结合
IVF_PQ 将倒排文件和乘积量化结合在一起,利用两者的优势来加速高维向量检索。具体流程如下:
量化与聚类:首先,数据集中的每个向量会被分为多个子空间,每个子空间进行乘积量化。接着,通过倒排文件将数据按簇组织。
查询流程:
查询时,首先根据查询向量找到相应的倒排表(即查询向量属于哪个簇)。
然后,在该簇内,使用乘积量化后的代码本来进行相似度计算,找到与查询向量最相似的向量。
这样,通过倒排文件限制搜索范围,并通过乘积量化精简计算过程,IVF_PQ 大大提高了大规模数据集上相似向量检索的效率。
HNSW
HNSW(Hierarchical Navigable Small World Graph)是一种基于图的索引算法,采用分层结构和小世界图理论,旨在高效地进行近似最近邻搜索。它通过构建一个多层次的图结构,其中每一层的节点连接关系不同,逐层精细化,从而提高高维数据集的搜索效率。
- 图的结构
HNSW 的图结构结合了两种技术:跳表(Skip List)和可导航小世界(NSW)图。
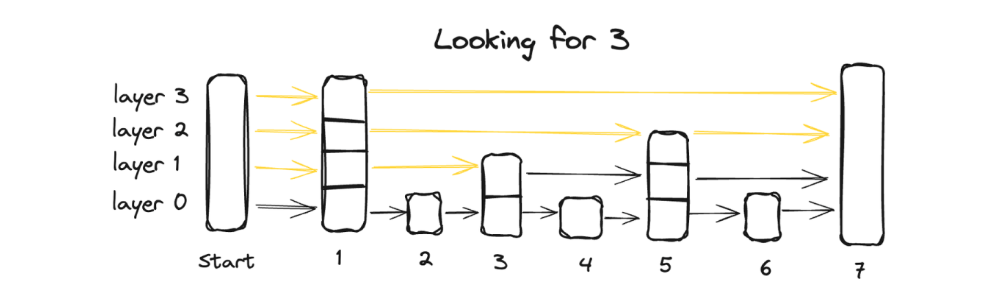
跳表特点:
多层链表:跳表的底层是一个完整的有序链表,存储所有元素。上层链表是下层链表的"抽象版",包含部分元素,随着层数增加变得更加稀疏。
逐层查找:查询时,从最上层开始查找,如果当前层无法找到目标元素,则跳到下一层继续查找,直到最底层。
可导航小世界(NSW)特点:
邻接列表:每个节点连接若干相似节点,称为邻接节点。每个节点都保存一个邻接列表。
遍历过程:从随机选定的入口节点开始,通过图的边逐步找到最接近查询向量的节点。
- HNSW 的工作原理
HNSW 将跳表的层次化结构与 NSW 的小世界理论结合起来,形成了一个高效的近似最近邻搜索算法。其工作分为两个主要阶段:索引构建和查询过程。
索引构建
图的层次结构:HNSW 构建一个多层图,每一层代表不同的搜索精度和速度。最上层图的节点较少,提供粗粒度的搜索;而底层节点则提供更精细的搜索,逐层提升搜索精度。
连接邻居:每个新加入的节点会选择若干个近邻节点进行连接,从而形成一个局部的小世界结构。通过选择性地建立邻接关系,确保了图的稀疏性和高效搜索。
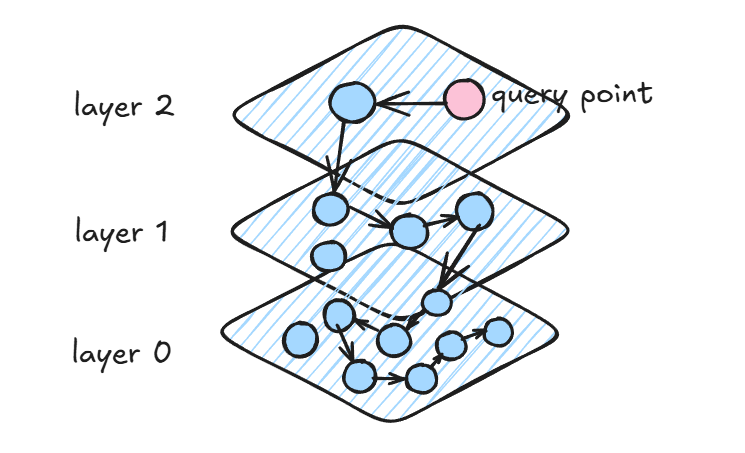
查询过程
逐层搜索:查询从最上层图开始,逐层向下进行。每一层会根据相似度从当前节点跳到相邻节点,逐步逼近目标位置。此时,查询会通过图中的边,利用跳表的方式,逐步接近查询向量。
局部优化:在最底层,HNSW 通过局部搜索策略,遍历当前节点的邻接节点,找到最接近查询向量的结果。
DiskANN
DiskANN 是一种基于磁盘的高性能向量近邻搜索算法,旨在解决大规模向量数据检索中的内存消耗问题。通过将轻量级的索引结构置于内存中,而将海量的原始数据和构建好的图结构存放在磁盘上,DiskANN 能够在保持高召回率和低时延的同时,大幅减少对内存资源的依赖。
DiskANN 的优势:
与基于内存的算法相比:如 HNSW 和 IVF,DiskANN 在资源消耗和可扩展性上有明显优势,能够在更低的资源消耗下提供相似的查询性能。
与基于聚类压缩的算法相比:如 IVF_PQ,DiskANN 在召回率和性能上保持高效,同时避免了因压缩而导致的召回率降低。
索引算法对比
下表总结了各索引算法的时间/空间复杂度和适用场景:
| 索引类型 | 时间复杂度 | 空间复杂度 | 精度 | 适用场景 |
|---|---|---|---|---|
| FLAT | O(N×D) | O(N×D) | 100% | 小规模数据,精确搜索 |
| IVF_FLAT | O(N×D/k) | O(N×D) | 高 | 中大规模数据,平衡精度和速度 |
| IVF_SQ8 | O(N×D/k) | O(N×D/4) | 中高 | 大规模数据,内存受限 |
| IVF_PQ | O(N×D/k×m) | O(N×D×m) | 中 | 超大规模数据,内存极度受限 |
| HNSW | O(log N×D) | O(N×D×M) | 高 | 高精度要求,内存充足 |
| DiskANN | O(log N×D) | O(N×D×α) | 高 | 超大规模数据,内存受限 |
其中:N 为向量数量,D 为向量维度,k 为聚类数量,m 为 PQ 子空间数量,M 为 HNSW 每层连接数,α 为内存比例因子。
索引选择指南
根据数据规模选择
小型数据集(<10万):使用 FLAT 索引,保证精确搜索,无需近似。
中型数据集(10万-1000万):使用 IVF_FLAT 或 HNSW,平衡精度和速度。
大型数据集(1000万-1亿):使用 IVF_SQ8 或 HNSW,考虑内存限制。
超大型数据集(>1亿):使用 IVF_PQ 或 DiskANN,优先考虑内存效率。
根据精度要求选择
高精度要求(>95%召回率):使用 HNSW 或 FLAT。
中等精度要求(90%-95%召回率):使用 IVF_FLAT 或 IVF_SQ8。
低精度要求(<90%召回率):使用 IVF_PQ,优先考虑速度和内存。
根据查询速度要求选择
实时查询(<10ms):使用 HNSW 或 IVF_FLAT(适当调参)。
近实时查询(10-100ms):使用 IVF_SQ8 或 IVF_PQ。
离线查询(>100ms):可以使用任何索引类型。
根据内存限制选择
内存充足:使用 HNSW 或 IVF_FLAT。
内存中等:使用 IVF_SQ8。
内存受限:使用 IVF_PQ 或 DiskANN。
Milvus 实战配置
环境准备
# 安装 Milvus
pip install pymilvus
# 启动 Milvus 服务(Docker 方式)
docker pull milvusdb/milvus:v2.3.4
docker run -d --name milvus -p 19530:19530 -p 9091:9091 milvusdb/milvus:v2.3.4创建 Collection
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection
# 连接 Milvus
connections.connect(host="localhost", port="19530")
# 定义字段
fields = [
FieldSchema("id", DataType.INT64, is_primary=True, auto_id=True),
FieldSchema("embedding", DataType.FLOAT_VECTOR, dim=768),
FieldSchema("text", DataType.VARCHAR, max_length=2000),
FieldSchema("source", DataType.VARCHAR, max_length=200)
]
# 创建 Collection
schema = CollectionSchema(fields, description="RAG documents")
collection = Collection("rag_documents", schema)创建索引
# HNSW 索引(推荐用于高精度场景)
index_params_hnsw = {
"index_type": "HNSW",
"metric_type": "IP",
"params": {"M": 16, "efConstruction": 256}
}
collection.create_index("embedding", index_params_hnsw)
# IVF_FLAT 索引(推荐用于中大规模数据)
index_params_ivf_flat = {
"index_type": "IVF_FLAT",
"metric_type": "IP",
"params": {"nlist": 1024}
}
collection.create_index("embedding", index_params_ivf_flat)
# IVF_SQ8 索引(推荐用于内存受限场景)
index_params_ivf_sq8 = {
"index_type": "IVF_SQ8",
"metric_type": "IP",
"params": {"nlist": 1024}
}
collection.create_index("embedding", index_params_ivf_sq8)
# IVF_PQ 索引(推荐用于超大规模数据)
index_params_ivf_pq = {
"index_type": "IVF_PQ",
"metric_type": "IP",
"params": {"nlist": 1024, "m": 8, "nbits": 8}
}
collection.create_index("embedding", index_params_ivf_pq)数据插入与检索
import numpy as np
# 生成示例数据
dim = 768
num_entities = 100000
embeddings = np.random.randn(num_entities, dim).astype(np.float32)
texts = [f"Document {i}" for i in range(num_entities)]
sources = [f"source_{i%10}" for i in range(num_entities)]
# 插入数据
collection.insert([embeddings, texts, sources])
# 加载 Collection 到内存
collection.load()
# 检索
search_params = {
"metric_type": "IP",
"params": {"ef": 64} # HNSW 参数
}
query_embedding = np.random.randn(1, dim).astype(np.float32)
results = collection.search(
query_embedding,
"embedding",
search_params,
limit=10,
output_fields=["text", "source"]
)
# 输出结果
for hits in results:
for hit in hits:
print(f"ID: {hit.id}, Score: {hit.score}, Text: {hit.entity.get('text')}")性能优化建议
索引参数调优:
HNSW:增大 M 和 efConstruction 可以提高精度,但会增加内存使用和构建时间。
IVF 系列:增大 nlist 可以提高精度,但会增加查询时间。
内存管理:
使用
collection.load(replica_number=N)启用多副本,提高并发查询能力。定期清理过期数据,减少内存占用。
查询优化:
根据业务需求调整
ef(HNSW)或nprobe(IVF)参数。使用分区(Partition)缩小检索范围。
监控与调优:
监控查询延迟和召回率,根据实际表现调整参数。
使用 Milvus 的监控工具分析性能瓶颈。
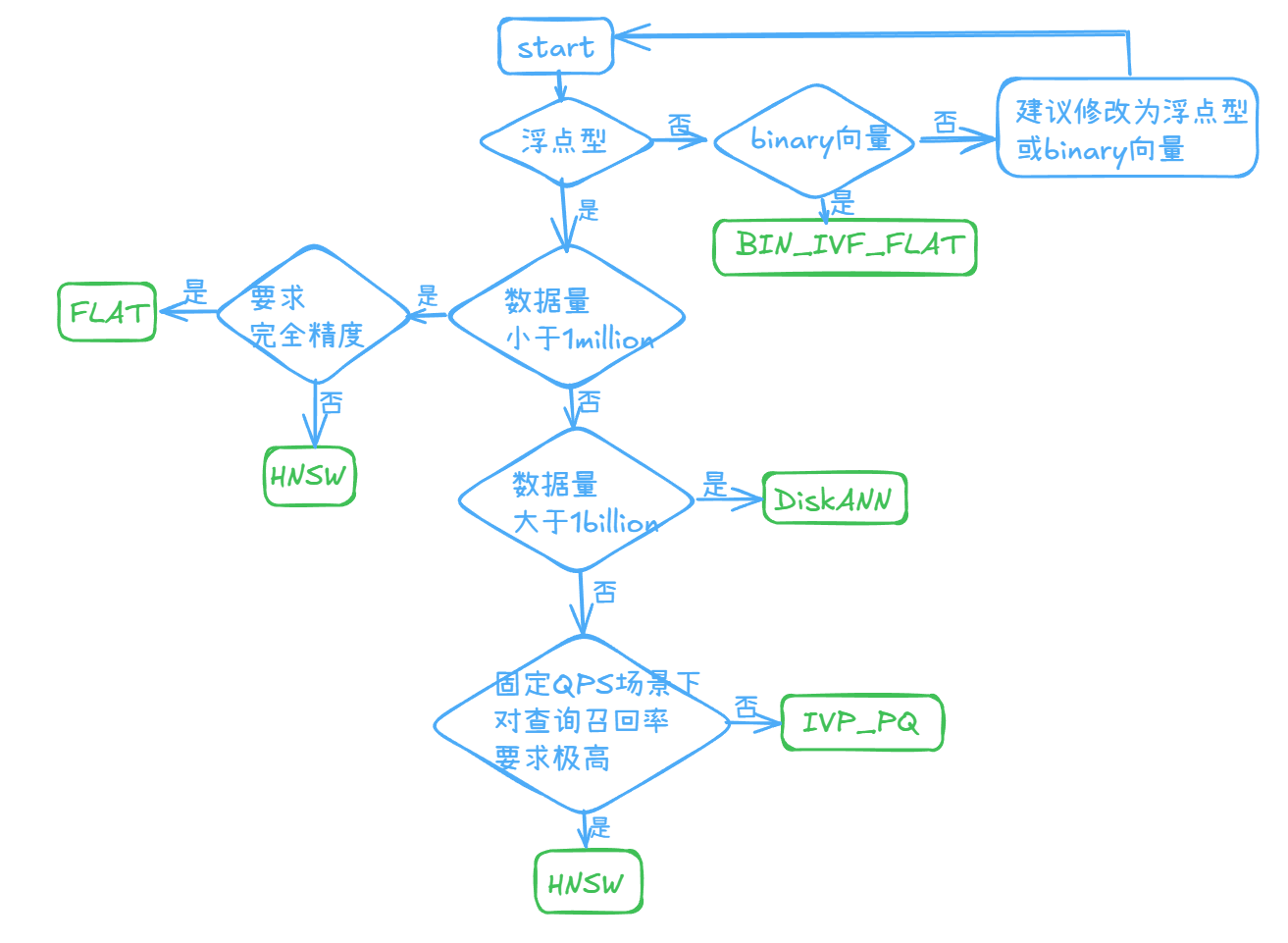
总结与建议
向量索引技术在大规模、高维度的非结构化数据检索中扮演了至关重要的角色。通过多种创新算法,不同场景中的检索效率得到了显著提升。这些索引技术有效解决了传统方法在处理海量数据时的局限,支持了高效的近似最近邻(ANN)搜索,尤其在 LLM、推荐系统、多模态搜索等领域表现出巨大的应用潜力。
选择合适的向量检索方式依赖于具体的应用需求和数据特性,需要在性能和效率之间取得平衡,下图是一些建议: