Long Context
Long Context(长上下文) 通过增加模型直接处理的文本长度来维持更多的上下文信息,需要通过模型训练来逐步拉升大模型能够接纳的输入文本长度。一般来说,把接受 4K-8K 输入 token 的 LLM 算作普通的 LLM,能够接受 10K~200K 甚至数百万的 LLM 叫做长上下文大模型。
现实中的如文档摘要、多轮对话等任务,需要 LLM 理解长文本序列,否则模型的 Perplexity(困惑度)将显著上升。但是长上下文将增加计算成本,且对显存需求更高。
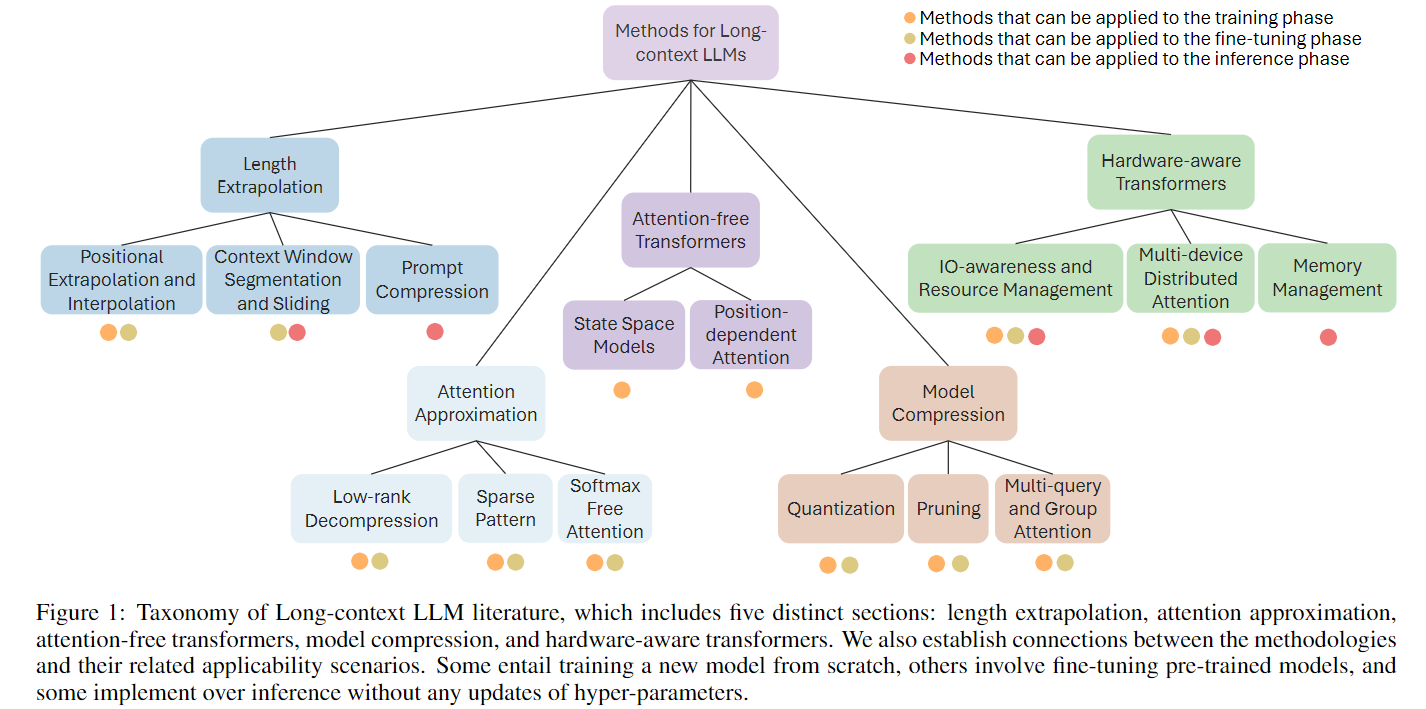
上图摘自论文《Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models》,将长上下文方法分为 5 类:
Length Extrapolation(长度外推):即"Train Short, Test Long"。如位置编码外推、上下文窗口分割和 Prompt 压缩,也是本章节介绍的重点。
Attention Approximation(注意力近似):旨在降低注意力依赖计算的复杂度,比如低秩分解和稀疏注意力。降低复杂度后,在有限资源的情况下可以输入更多的 token。
Attention-free Transformer:在不依赖于传统注意力机制的情况下提供 token 之间依赖信息的计算方法,如基于 RNN 的状态空间模型 SSM,最近比较火的 Mamba。
模型压缩:压缩模型减小参数量和计算量,进而可以处理更长的上下文。例如模型量化、剪枝。
硬件感知的 Transformer:主要从 I/O、资源管理和多设备等方面提高计算效率,如 FlashAttention。
位置外推
位置外推通过调整与输入 token 相关的位置嵌入(Position Embedding)的技术,从而修改这些 token 在模型体系结构中的定位和解释方式,从而在推理时能处理超过其训练序列长度的输入序列。
最直接的外推即在训练时预留多几维设置为 0,推理时再改为其他值,但是这些维度没有被训练过,会导致推理时性能严重下降。
通过位置编码外推的方法已经在 1.4 位置编码 介绍了,在这里不再赘述。
插值
将推理时的位置索引进行下采样或缩放,就是把 2k 的位置编码对应到 1k。通过这种方式,推理时的位置索引被映射回了模型训练时的范围内,从而帮助模型更好地处理这些原本超出其处理能力的输入序列。
线性内插
比如通过除以 2,将 4 位转成 3 位,导致的结果是最后一位更加拥挤,相邻数字的差距变成了 0.5。虽然经过微调后效果不会明显下降,但是当处理范围进一步增大时,相邻数字差异更小,并且相邻差异只集中在个位数,其他位相邻差异仍是 1,导致维度之间分布不一样,增大模型学习难度。
进制转换
可以通过进制转换,既不用新增维度,也可以保持相邻间距。比如采用 16 进制取代 10 进制。
重新思考 RoPE
首先给出苏神的定义:位置
举个例子:给定一个 10 进制的数字
又知道 RoPE 的定义中有以下 cos 序列(sin 也同理):
cos 序列就可以表示为:
至于模运算,它的最重要特性是周期性,cos 刚好也是周期函数。所以,除掉取整函数这个无关紧要的差异外,RoPE 其实就是数字
基于以上结论,后续介绍的内插就是将
旋转位置编码(RoPE)的矩阵乘法形式:
优化后的逐元素相乘形式:
其中,$$\theta_i = 10000^{-2i/d}, \quad i \in [1, 2, \ldots, \frac{d}{2}].$$
位置插值
- 参考文章:Extending context window of large language models via positional interpolation
PI 通过直接将位置索引缩小,这对于 RoPE 等位置编码更合适,并且可能需要较少的训练,因为没有添加可训练参数,使得最大位置索引与预训练阶段的上下文窗口限制相匹配。其本质就是在相邻的整数位置上插值位置索引,因为位置索引可以应用在非整数的位置上(而非在训练位置外进行外推)。
- 区别于线性内插,PI 仍保留了 4096 个位置索引,只不过索引之间距离变成 0.5,而前者只有 2048 个索引,多出来的索引被压缩到了最后一位。
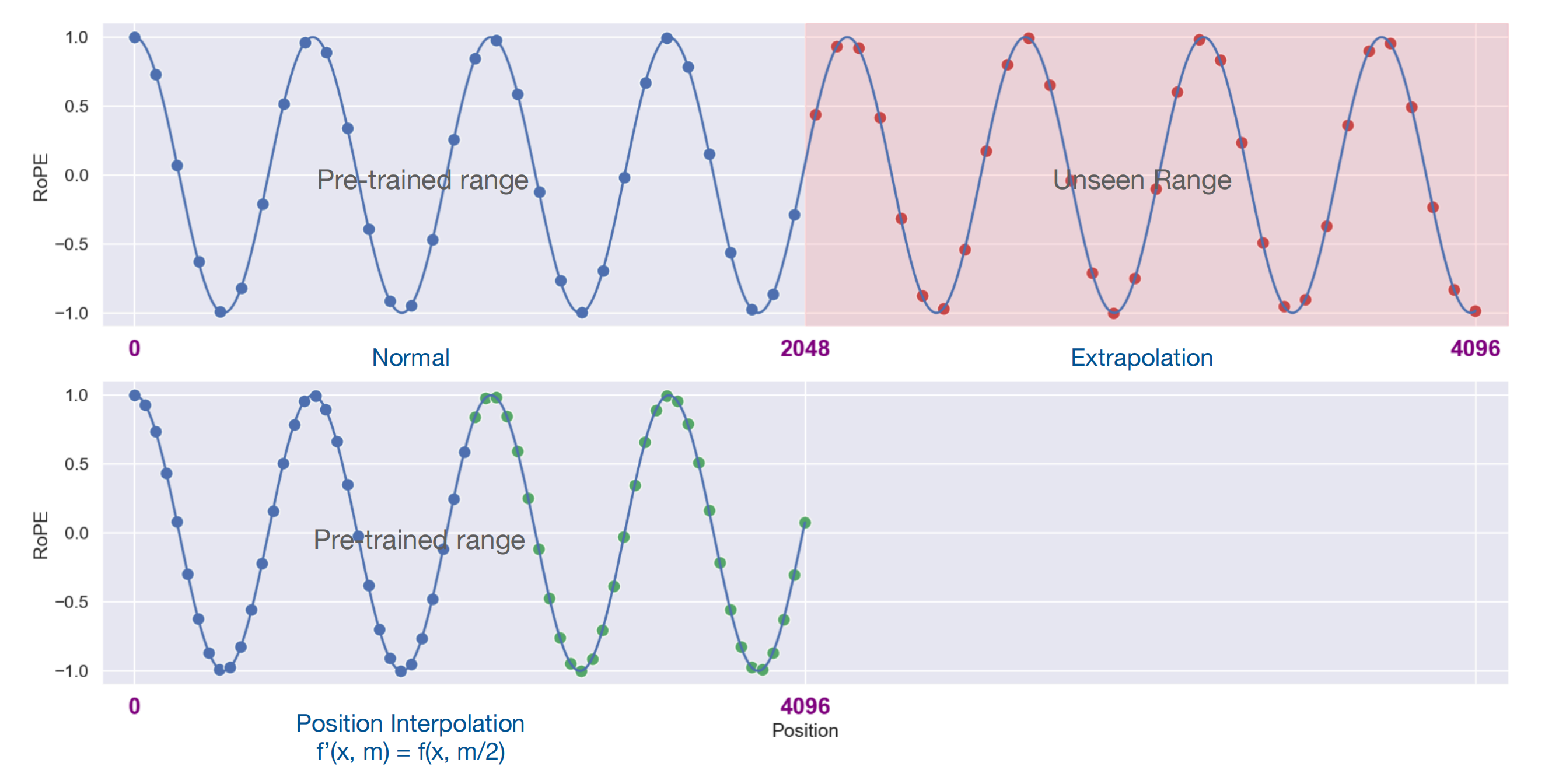
使用 PI 后,位置
位置插值法存在的问题
与 RoPE 一起使用时,RoPE 中的每个维度
NTK-aware 插值
核心思想是:高频外推,低频内插。
对于
而对于最高频项
NTK 插值存在的问题
由于它不仅仅是一种插值方案,一些维度被轻微外推到"超出边界"的值,因此使用"NTK-aware"插值进行微调的结果不如 PI。
此外,由于存在"越界"值,理论尺度因子
并不能准确描述真实的上下文扩展尺度。在实践中,对于给定的上下文长度扩展,尺度值 必须设置得高于预期尺度。
NTK-by-parts插值
波长:维度d上嵌入的RoPE,执行完整旋转(
"盲"插值方法不关心不同维度对应的不同波长,比如像PI和"NTK-aware"插值,对所有RoPE维度的没有做针对性的处理(因为它们对网络有相同的影响),而其他方法(如YaRN),定义为"有针对性的"插值方法。
对RoPE有以下观察:
给定上下文大小L,有一些维数d的波长长于预训练期间看到的最大上下文长度(
),这表明一些维数的嵌入可能在旋转域中不均匀分布。当波长很长时,这些维度上的嵌入几乎不变,可以认为它们保持了绝对位置信息,即每个位置的嵌入不因相对位置变化而变化;当波长较短时,嵌入会在较短的距离内完成多次旋转,这使得这些维度上的嵌入反映的是相对位置信息,即它们可以捕捉到标记之间的相对距离变化。 采用RoPE进行拉伸时,所有的token变得更彼此接近,因为
, 减小会导致两个向量的内积变大,变得更加接近。从而损害模型处理邻近token位置时的性能。
为了解决以上问题,对高频率的维度不插值,对更低频率的维度插值。
如果波长
比上下文长度 L 小得多,此时不插值 如果波长
等于或大于上下文长度 L ,此时只做插值,不做任何外推 两者之间的维数可以兼备
定义比率
- 如果
,比如 ,意味着波长大于上下文长度,则将线性插入一个尺度 (完全像PI,避免任何外推) - 至于如果是
,则不插值
接下来,定义斜坡函数
固定缩放因子s可能会导致,模型在长度小于 L 时可能出现性能折扣,当序列长度大于 L' 时可能出现突然退化。因此提出动态缩放,在每次前向传递中,位置嵌入更新缩放因子 s=max(1,l'/L),其中 l' 是当前序列的序列长度。
yarn插值
在对logits进行softmax操作之前引入温度可以统一地影响困惑度,无论数据样本和扩展上下文窗口上的token位置如何。具体来说,将注意力计算修改为:
短上下文:
t较大,插值强度低,保持原始位置编码特性。长上下文:
t较小,增强低频段的插值强度,避免位置编码碰撞。
在训练和推理时没有引入额外的开销,结合NTK-by-parts插值就得到了Yarn插值。
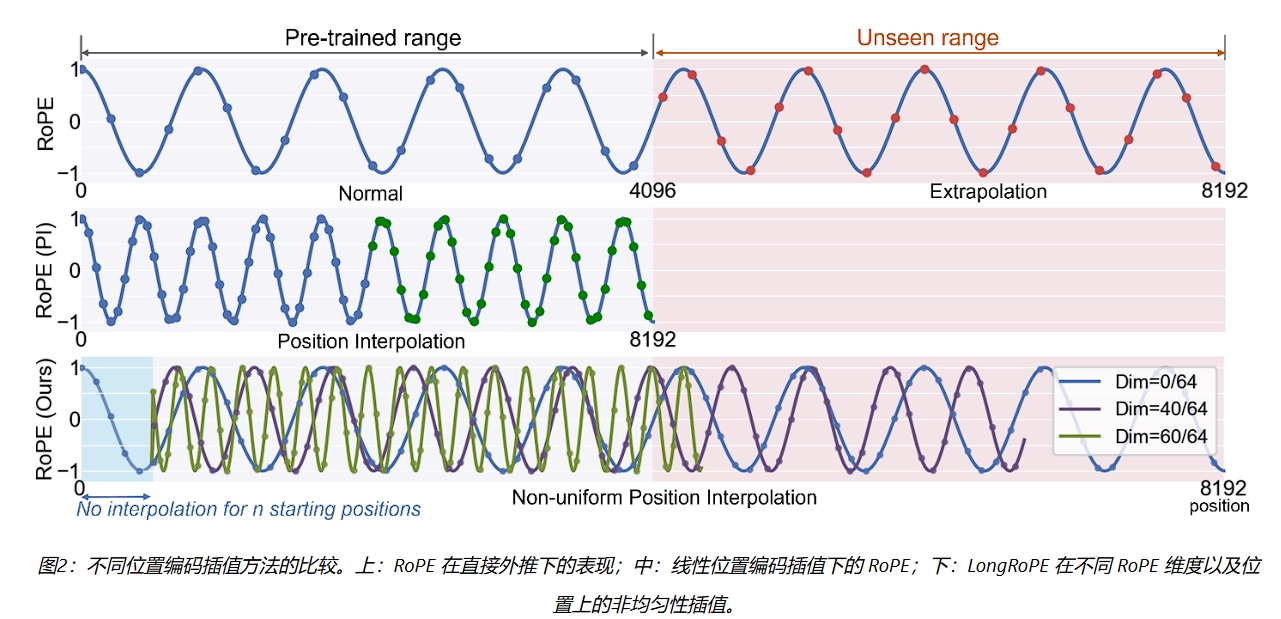
LongRoPE
非均匀位置插值:LongRoPE中发现,有效的位置编码插值应考虑两种非均匀性:不同的RoPE维度(
)和不同的token位置( )。低维和初始token位置存储着关键信息,因此需要进行更少程度的插值。相比之下,高维存储的信息相对较为稀疏,可进行较大程度的插值。通过搜索RoPE每个维度以及不同token位置的旋转角度缩放因子,有效地保留了原始 RoPE 位置编码中的信息。这种方法最大程度地减小了位置插值引起的信息损失,从而为微调提供了更好的初始化。 上下文渐进式扩展:LongRoPE首先在预训练的LLM上进行256k长度的微调,然后对微调后的模型进行第二次位置插值,以实现2048k的上下文窗口。
短上下文窗口性能恢复:在扩展到2048k上下文窗口后,LongRoPE通过调整RoPE位置插值因子来恢复短上下文窗口的性能。LongRoPE在扩展后的大模型上对8K长度内的RoPE缩放因子进行了重新搜索,以鼓励在较短上下文长度上进行较少的位置插值。在推理过程中,大模型可根据输入长度动态调整相应的 RoPE 缩放因子。
上下文窗口分割
通过将上下文分割成段,并采用滑动窗口方法来处理上下文。
子序列恢复算法(Parallel context windows for large language models)
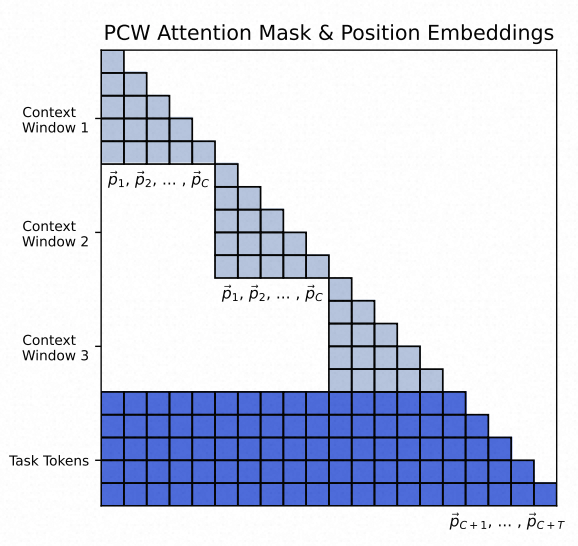
LLM的输入分为上下文token(上下文文档或者检索到的文档)和任务token(要分类的句子或者问题本身)。
PCW使用的是Decoder框架,输入和输出都在Decoder侧。
- 位置编码:LLM的上下文窗口长度为N,任务token长度为T,上下文的窗口长度为C=N-T。对于要处理的长上下文,将其分割为B段,每一段长度为C,总的长度为BC+T。PCW位置编码为:
在解码时丢弃了上下文多段文本之间的位置关系,解码时只知道上下文多段文本都是在解码器之前,但无法区分文本之间的位置。不过因为上下文每段文本复用了相同的位置编码,因此位置编码的长度大幅降低,也就降低了对位置编码外推性的需求。
- 注意力矩阵:基于PCW编码,在执行注意力计算时,每个窗口内部进行自回归,然后将结果进行拼接,各个窗口复用同一个位置编码。任务token和所有上下文中的token都计算注意力。
PCW需要的计算复杂度正比于并行上下文数量B,但注意力矩阵很稀疏,多窗口并行的效率很高。
PCW的缺点:
但是在长文本QA问题上表现比较一般,当上下文存在多段文本且无明显关系时,正确答案中会混杂很多无关的文本变短。
PCW是在输入层就开始对超长上文进行Attention,因为不同上文的位置编码相同,一定程度上会让解码注意力变得非常分散,导致注意力的熵值变高,解码的不确定性变大,更容易出现乱码。
NBCE
假设T是要生成的token序列,S1,S2,⋯,Sn是相对独立的Context集合(比如n个不同的段落,至少不是一个句子被分割为两个片段那种),假设它们的总长度已经超过了训练长度,而单个Sk加T还在训练长度内。我们需要根据S1,S2,⋯,Sn生成T,即估计p(T|S1,S2,⋯,Sn)。
基于独立假设的贝叶斯公式,即朴素贝叶斯:
这里
另外根据贝叶斯公式:
这里的p(T|Sk)和p(T)都可以直接用现有的LLM进行计算,且不涉及长文本。
记
就可以得到:
在阅读理解场景中Max Pooling配合β=0.25,用Greedy Search总体表现比较好,然而Random Sample出来的结果基本不可读。Random Sample是"按照分布采样",它的效果差说明Max Pooling的结果不是一个合理的分布;而Greedy Search只关心最大概率者,而不关心分布的合理性,它的效果好告诉我们概率最大的token正确性较高。
本质是在做Average Pooling,也可以换成其他的Pooling方法:
概率越大说明结果的不确定性越低,将Pooling方式改为直接输出不确定性最低的那个分布,就得到了NBCE。
NBCE中不同Context的预测结果通过方法P聚合(或者说投票)在一起(权重为β+1),并减去无Context的预测结果(权重为β)。之所以要减去无Context预测结果,是为了让模型更加倾向于结合Context而不是纯粹根据自身知识储备来回答。
NBCE存在的问题:
与PCW类似,当上下文增加时,输出的结果不准确,具体表现为主题相关,但是作为问题的答案来说是错误的。并且由于无法识别Context输入顺序,在故事续写等场景表现欠佳。
PCW大致上就是Average Pooling版的NBCE,实测也发现它跟Average Pooling版的NBCE有着相似的缺点。
streaming-LLM
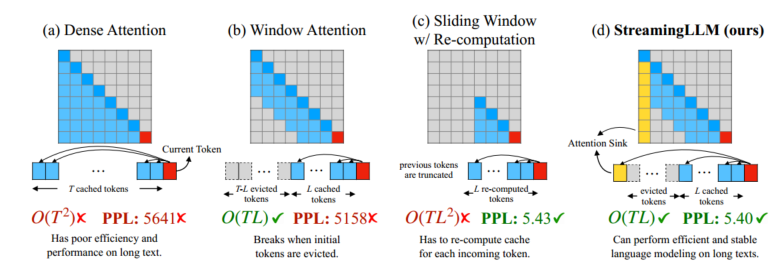
a) 密集注意力:时间复杂度为O(
),当推理文本超过预训练长度时,困惑度大幅度上升 b)** 窗口注意力**:只维护最近的L个token的KV,但是当序列长度超过缓存大小时,失去第一个token的KV,会导致困惑度增加。
c) 滑动窗口与重新计算:为每个新的token重建最近token的KV状态(这样一直保持有初始token)。虽然它在长文本上表现良好,但它的
复杂性(源于上下文重新计算中的二次注意力)使得它相当慢。 d)streaming-LLM:保留attention sink(注意力汇聚,汇聚在初始的几个tokens) 与最近的token结合,用于稳定的注意力计算。
作者观察到大量的注意力得分被分配给初始的token,即使它们与任务的相关性不高(即模型重视初始tokens的绝对位置,而不是它们的语义价值)。主要原因是因为Softmax操作,要求所有上下文token的注意力分数总和为1。因此,即使当前任务和许多先前的token不匹配,模型仍然需要在某个地方分配这些不需要的注意力分数,使得分数总和为1。由于初始token对几乎所有后续token都是可见的,所以这些额外的注意力都汇聚在初始的token上。
StreamingLLM将注意力汇聚的前4个初始token和滑动窗口的KV结合在一起,可以有效地推广到无限长的序列长度。
StreamingLLM在确定相对距离和添加位置信息时,关注缓存中的位置而非原文,以保障模型的效率。 例如,如果当前高速缓存具有token[0,1,2,3,6,7,8]并且正在解码第9个token的过程中,则分配的位置是[0,1,2,3,4,5,6,7]。而不是原始文本中的位置,即不是[0,1,2,3,6,7,8,9]。
为了避免模型过度关注初始的token:
引入一个全局可训练的注意力汇聚token。
修改softmax函数:不再使用真实的权重概率向量, 允许所有位置的attention值都很低。
提示压缩
对于LLM,越详细的prompt,往往效果越好。但是当prompt(在下图的Rag场景中,上下文一般指prompt)长度过长时,一方面耗时更长;另一方面由于检索到的很多内容可能与答案无关,LLM需要结合context对rerank重新排名后的context进行理解并生成答案,当context长度过长时效果较差。
如下图所示,右下角的prompt提示压缩能有效解决这些问题,只保留prompt中有价值的token。
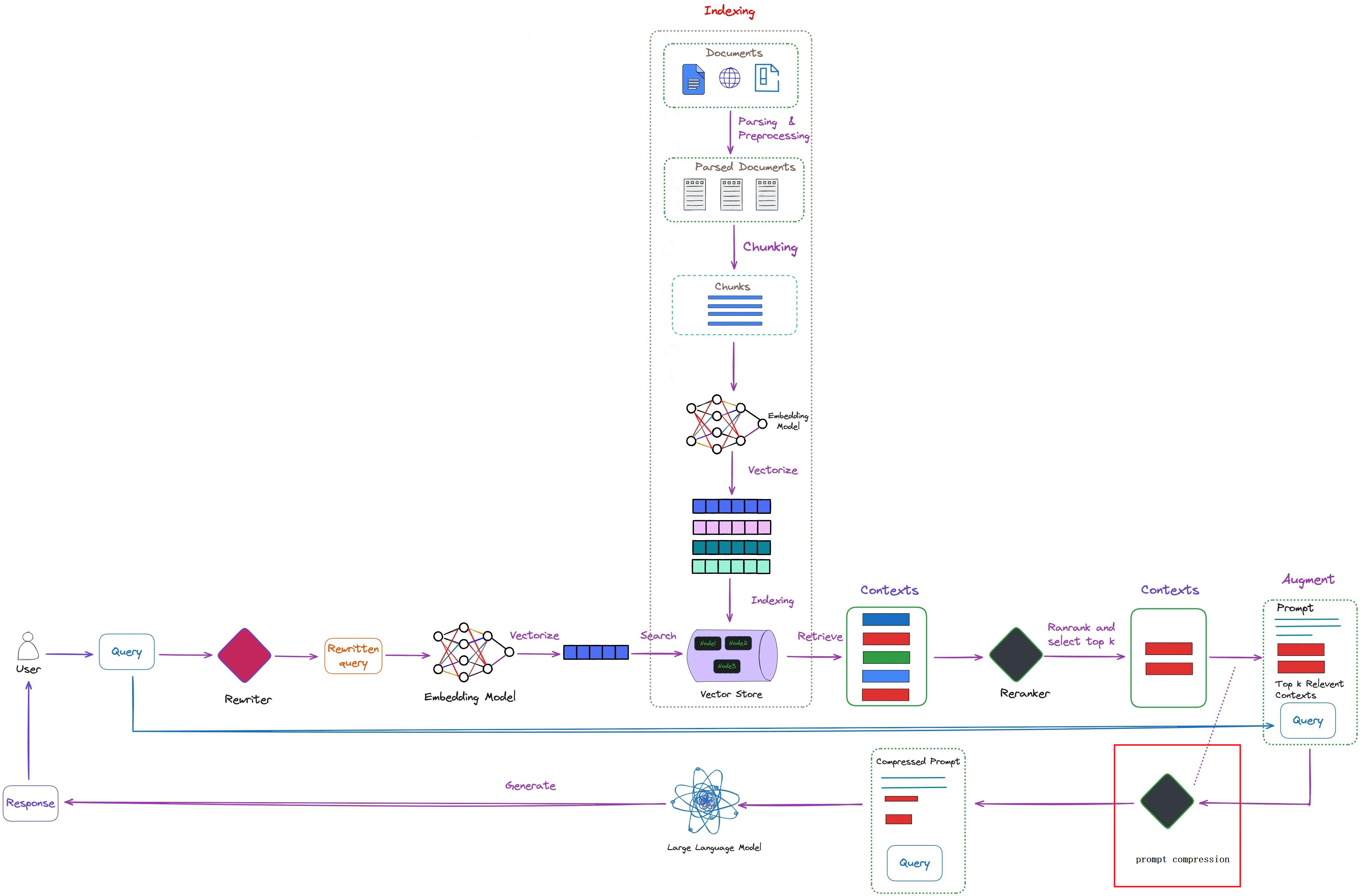
prompt压缩主要可以分为以下几类:
基于信息熵(information entropy)/ 困惑度(perplexity):使用小模型计算原始prompt中每个token的困惑度,删除困惑度较低的标记。例如Selective Context、LLMLingua 和 LongLLMLingua。
基于 soft prompt tuning :引入一组可学习的连续向量(通常称为"soft prompts"),在下游领域对LLM进行微调,但不能应用于黑盒LLM。如AutoCompressor。
基于数据蒸馏:先进行数据蒸馏,再训练模型生成可解释性强的摘要,适用于黑盒LLM。如LLMLingua-2 和 RECOMP
Selective Context
作者观察到即使缺失了部分包含非关键信息的上下文,大模型依然能对用户查询进行准确作答。Selective Context 建立在这种思想之上。
Selective Context 策略采用小型语言模型(SLM),来计算给定上下文中各个词汇单元(比如句子、短语或词语)的自信息值((self-information)进一步)。然后,基于这些自信息值评估各单元的信息含量。通过仅保留自信息值较高的内容,Selective Context 为大语言模型(LLM)提供了更为简洁、高效的 context representation 。
自信息量:量化事件传达的信息量,设随机变量X的概率密度函数为p(X),对于
越罕见的事件,由于包含了更多新颖的信息,传达的信息越多。
训练流程:
使用小型语言模型(SLM)计算出上下文中每一个 token 的自信息值。
接着将token合并成句子/短语,合并后句子/短语的自信息量为每个token的和。
之后将句子/短语按照信息量降序分布,只保留包含前p%信息量的句子/短语,从而达到优化的目的。
Selective Context存在的问题:
只根据自信息量选择关键信息,可能无法完全捕捉关键信息,并且忽略了压缩后上下文内容之间的连接性,可能对模型预测造成影响。
没有考虑大模型与压缩prompt的小模型的相关性。
计算自信息量会导致一定的计算开销。
LLMLingua
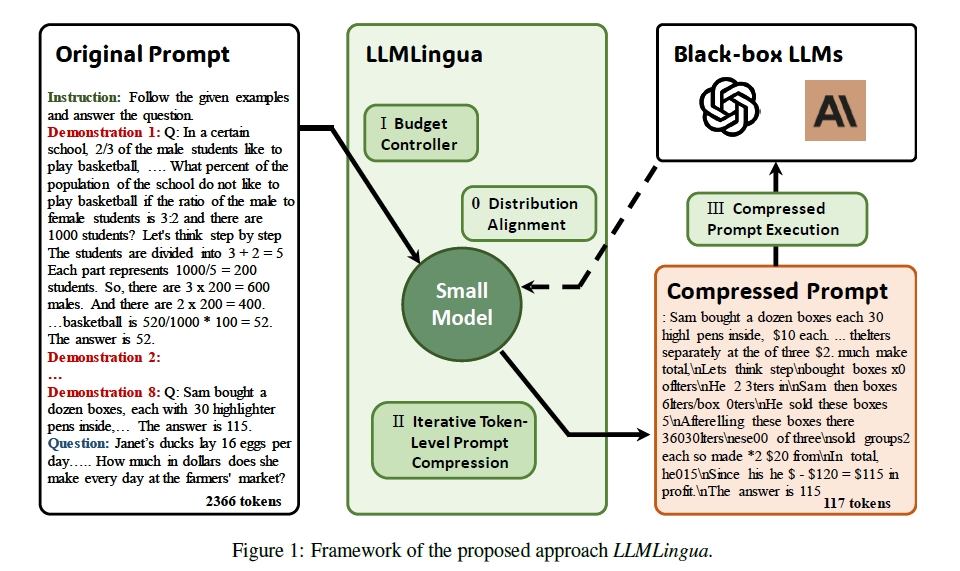
问题定义:
LLMLingua 采用预算控制器为原始提示的各个组成部分(例如指令instruction、演示demonstration(其实就是样例)和问题query)动态分配不同的压缩比。LLMLingua执行粗粒度、演示级压缩,即使在高压缩比下也能保持语义完整性。此外,LLMLingua 引入了用于细粒度提示压缩的令牌级迭代算法。
Budget Controller预算控制器
为原始prompt的不同部分动态分配不同的压缩率。
用户查询和系统指令要保持较高的信息密度,用较低的压缩比率,确保核心信息的完整留存
演示样例部分可实施更高比率的压缩,剔除不必要的冗余信息。
之所以要采用粗粒度、演示级压缩用于demonstration的压缩,是因为一方面过多冗余的demonstration会占据instruction和query的位置,后者对生成答案的影响更大。另一方面token级别的压缩可能导致prompt过于琐碎。
训练流程如下:
计算演示样例的压缩比例
利用小型语言模型(如 GPT-2 或 LLaMA)计算原始演示样例集合中每个演示样例的困惑度(perplexity),按perplexity进行排序。
迭代选取演示样例加入集合D。
压缩演示样例后,剩余的budget加到系统指令和用户查询中。
Algorithm 1 Pseudo code of Token-level Subsequence Recovery.
Input: The original prompt
Output: The final response list
ITPC迭代令牌级提示压缩
存在问题: 上一阶段按照困惑度(perplexity)进行压缩,依赖于token之间的独立性假设(也就是n-gram,假设token之间是彼此独立的,其出现概率只跟其前面的n-1个token有关,而跟其他token无关)。这一假设忽略了token之间复杂的关系,这种关系对于理解上下文和保持语义的完整性至关重要。
目的:对prompt进行进一步的细颗粒度的压缩,得到最终的输出prompt。
ITPC算法:在压缩期间更精确地评估每个标记的重要性,通过迭代处理提示中的每个片段并考虑当前上下文中每个标记的条件概率来实现这一点。这种方法有助于更好地保留令牌之间的依赖关系。
将Budget Controller输出的
可以根据每一段的压缩率和困惑度分布计算阈值
每一段中每个困惑度大于阈值
Distribution Alignment
用于消除压缩用的小模型
LongLLMLingua
LLMLingua 在压缩过程中没有考虑用户查询,可能会保留不相关的信息。LongLLMLingua通过将用户问题纳入压缩过程来解决这个问题。再LLMLingua的基础上,做了以下的改进:
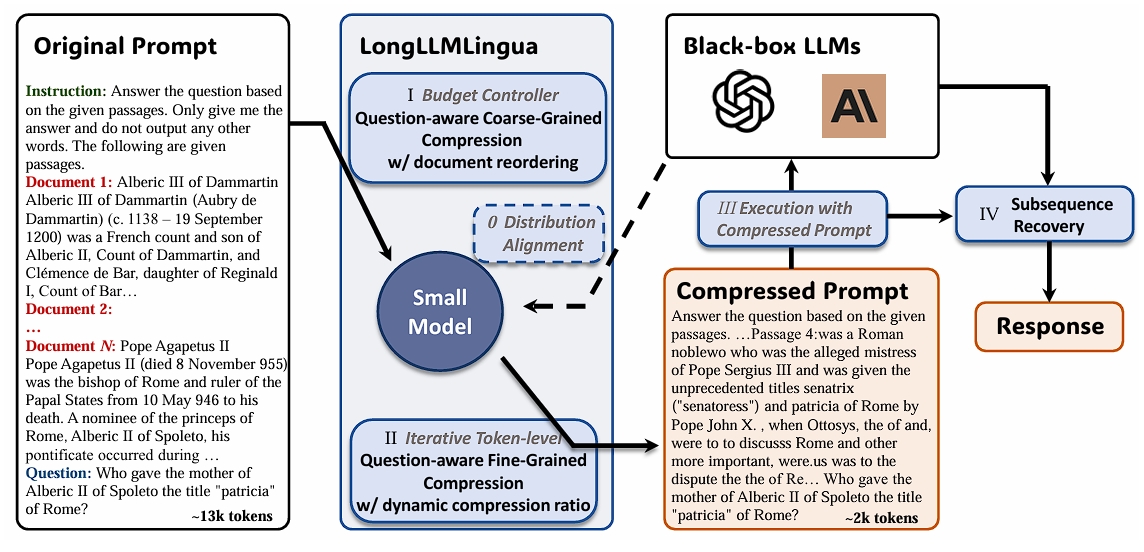
基于问题的粗粒度压缩
通过找到一个指标
因此这篇文章用
基于问题的细粒度压缩
为了消除query自身信息熵的影响,使用不带查询的上下文困惑度与带查询的上下文困惑度之间的差作为当前token的"重要性",来对文档进行细粒度压缩。本文使用对比困惑度,如果问题加入进来以后,某个词困惑度大幅度下降,则说明这个词于问题高度相关:
实验证明高对比困惑度的token与question更相关。
文档重新排序
实验结果表明,LLM倾向于使用提示开头和结尾的内容,而忽略中间的内容。因此将粗粒度压缩后的结果按照
动态压缩比
LLMLingua对所有document使用同样的压缩比。LongLLMLingua 使用粗粒度压缩的重要性分数来指导细粒度压缩期间的预算分配。
首先使用 LLMLingua 的预算控制器设置保留文档的初始预算。然后,在细粒度压缩阶段,动态地将压缩预算分配给每个文档。LongLLMLingua 实施了一种线性调度方法,这种分配基于文档重要性得分的排名指数
where
保证关键信息完整
在细粒度压缩过程中,可能会压缩一些关键名词,比如2009被压缩成209,导致生成的答案有问题。本文提出子序列恢复算法:
遍历大语言模型(LLM)响应内容中的每一个词元(token)
,从中选取在压缩提示词 中出现的最长子序列 ; 在原始提示词 x 内,寻找与
匹配的最大公共最短子序列(maximum common shortest subsequence) ; 将大语言模型(LLMs)响应内容中的相应词元
替换为原始的 。

AutoCompressor
通过增加词汇量和利用"summary tokens"和"summary vectors"来提炼大量上下文信息,进而精调现有的模型结构。具体来说,通过递归生成 summary vectors 来处理长文档,这些 summary vectors 作为软提示词(soft prompts)被传递给后续的所有文档片段。
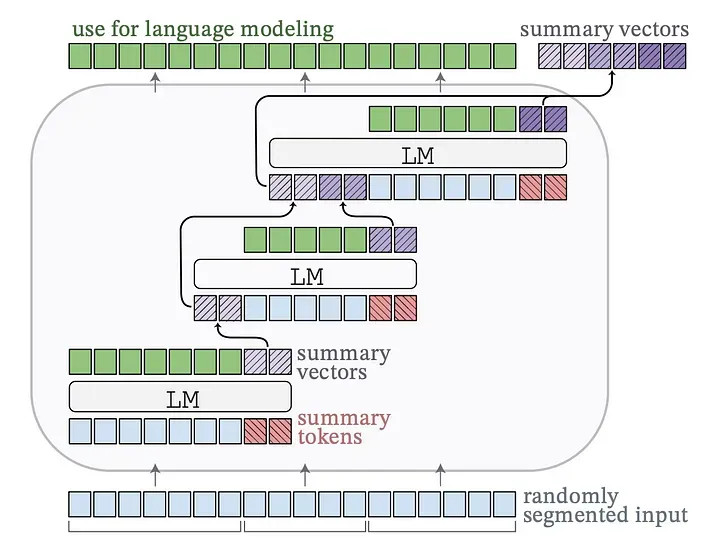
训练流程:
词汇扩展:在这一步骤中,我们将 **"summary tokens" **加入到模型现有的词汇库中。这些 tokens 的作用是帮助模型将庞大的信息量压缩成更紧凑的向量表征。
文档分割 :待处理的文档被切割成若干小段,每一小段后都会附加有 summary tokens 。这些 tokens 不仅携带了本段的信息,还包含了前面所有段落的摘要信息,实现了摘要信息的连续积累(summary accumulation)。
微调训练 :采用无监督训练的方式,根据当前片段前的 tokens 序列以及之前片段的摘要向量(summary vectors),预测下一个单词。
反向传播 :AutoCompressor 在每个文档片段上运用 backpropagation through time(BPTT)(对于每一个时间步,BPTT 都会计算损失函数关于当前时间步和所有之前时间步参数的梯度,然后将这些梯度反向传播回网络,以更新参数。详见《https://zhuanlan.zhihu.com/p/129336512》) 和 gradient checkpointing。反向传播针对整个文档进行,使得模型能够全面理解并学习到整个上下文之间存在的关联。
LLMLingua-2
基于困惑度的方法存在以下问题:
(1) 用来计算困惑度的小型语言模型与提示词压缩的实际目标不一致,也就是小模型能力不足。
(2) 这一方法仅依赖于单向的上下文信息,而这或许无法覆盖提示词压缩所需的所有必要信息。
针对第一个问题,LLMLingua-2 引入了数据蒸馏流程。该流程从大语言模型中提取知识,在不丢失关键信息的情况下压缩提示词。同时,它还构建了一个 extractive text compression dataset,从原始文本中挑选出最重要的句子、短语或词汇,直接组成一个较短的版本,以保留原文的主要信息和意义。在这样的数据集上进行训练,有助于小型语言模型更精准地对齐提示词压缩的需求。
面对第二个问题,LLMLingua-2 采取了一种创新策略 ------ 将提示词压缩转化为token分类任务。这一策略确保了压缩后的提示词能忠实地反映原始提示词的意图。它选用 transformer 的编码器作为底层架构,能够充分利用完整的双向上下文信息(bidirectional context),捕捉到进行提示词压缩所需的全部必要细节。
数据蒸馏
目的是从大语言模型(比如 GPT-4)中抽取知识,以便在不丢失基本信息的情况下实现有效压缩提示词。作者精心设计了一个提示词(提示词的设计也就是提示工程),指导模型在不向生成文本中引入新词汇的前提下,剔除原始文本中的冗余词汇,从而实现文本的压缩。
观察到在处理非常长的文本时,GPT-4 倾向于采取高比例的压缩策略,可能是因为其处理长文本的能力有限。这种激进的压缩策略往往伴随着大量信息的流失,可能严重影响接下来的任务执行效果。为了解决这个问题,LLMLingua-2 引入了一种分块压缩(chunk compression) 技术,即先将长文本拆解为若干个不超过 512 tokens 的小文本块,再分别对每一小文本块进行压缩处理,由 GPT-4 来完成这一过程。
数据标注
由于GPT-4生成的结果需要与原始文本"对应上",才能构建token级别分类模型。因此数据标注的目的就是为原始文本里的每个 token 标上一个二元标签,以此判断压缩后该字符是否应该被保留。LLMLingua-2 采取了滑动窗口策略(sliding window) ,以此来限定搜索范围。同时,还引入了模糊匹配技术(fuzzy matching) ,有效处理了 GPT-4 在提示词压缩过程中对原始词汇可能做出的细微改动。
质量控制
质量控制环节采用了两个关键指标来评估通过 GPT-4 蒸馏生成的压缩文本,以及自动标注标签的优劣:
Variation Rate(VR):衡量压缩后的文本与原始文本相比,有多少比例的词汇发生了改变。
Alignment Gap(AG),衡量自动标注的标签的精准程度。
压缩器训练
本质上就是做二元分类问题,预测每个token保留或者丢弃的概率。模型采用transformer 编码器(例如bert)+ 一个分类层,将每个token输出的logits作为其"保留"的概率,只保留大于阈值的token。
RECOMP
RECOMP[10]是一个建模在RAG场景中的模型压缩方案。其主要核心是3个部分+2个模型:抽取型压缩器擅长从已检索的文档中精挑细选出有价值的部分 ;而概括型压缩器则通过融合多篇文档的精华,自动生成摘要。
抽取型压缩器:采用双编码器模型(bi-encoder),将文档和用户查询都转换成固定长度的向量,计算每个文档和查询之间的内积来衡量文档和查询之间的相似度,筛选召回的文档。
概括型压缩器:采用Encoder-Decoder模型,对用户查询和筛选后的文档进行摘要。