Chunking-free RAG
参考论文:《BGE Landmark Embedding: A Chunking-Free Embedding Method For Retrieval Augmented Long-Context Large Language Models》
RAG 从大规模语料库中检索相关信息,将长文本压缩成简洁、关键的输入形式,以在不直接修改模型的情况下扩展上下文。为了提高检索效率,RAG 在建库的时候需要将长文本拆成小块,为每个块生成 embedding,通过比较用户查询和文档之间的 embedding 的相似度来检索最相关的块并作为输入。
分块带来了严重的问题:
破坏上下文连贯性:长文本被切割成不连续的部分(为了尽可能保证连续性,每一块可以有一些重复的),会破坏上下文的完整性。当模型需要理解段落中的复杂关系或连续语义时,分块会使得这些语义信息被分散,导致嵌入表示的准确性降低。
信息不完整:检索系统容易选择显著性较高的块,然而其他重要但不显著的块可能会被忽略。这样一来,模型可能无法获取完整的背景信息,影响检索的完整性。
为了解决分块带来的问题,提出了一种 Landmark Embedding 的方法,在 chunking-free 的情况下实现 RAG。
基础知识
大模型生成的过程可以用
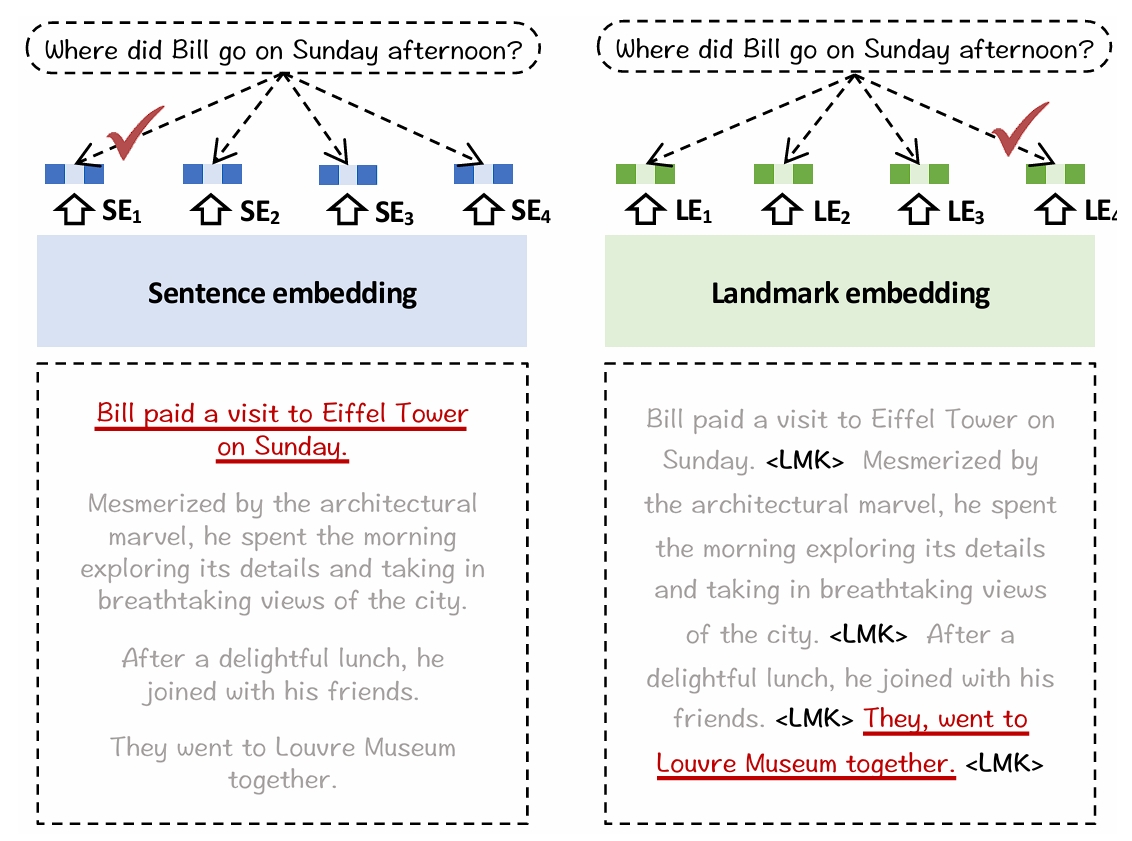
Landmark Embedding 提出一种不需要分块的检索方法
Chunking-Free 架构
假设原始的上下文由 n 个句子组成:
采用大语言模型(LLaMA-2-7B)对 LMK 和用户 query 进行编码,表示为:
基于上述结果,用户 query 和每个句子之间的相关性表示为两个嵌入的内积:
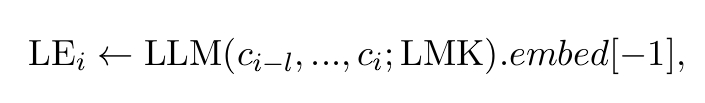
Landmark Embedding 详细原理
Landmark Embedding 的核心思想是在每个句子末尾添加一个可学习的标记(Landmark),该标记通过对比学习训练,能够聚合其所在句子及上下文的语义信息。具体来说:
Landmark 标记的作用:Landmark 是一个特殊的 token,它不携带实际的语义内容,而是作为句子的"代理"。通过训练,Landmark 能够学习到其所在句子的核心语义信息,以及与相邻句子的上下文关系。
编码过程:对于每个句子
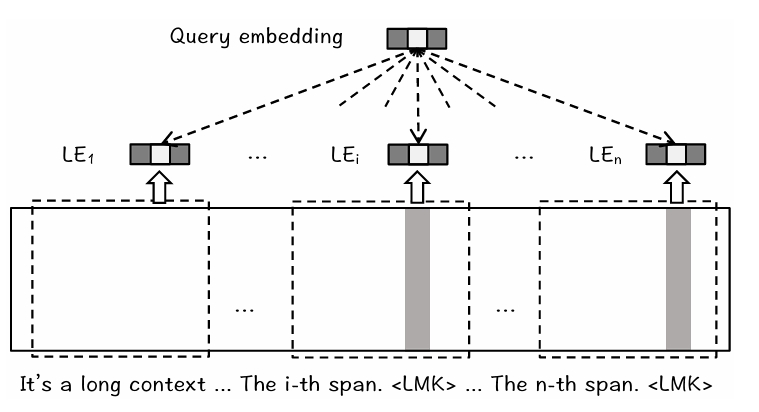
,将其与前 k 个句子 一起输入编码器,同时在末尾添加 LMK_i。编码器输出的最后一个 token 的隐藏状态即为该句子的 Landmark Embedding 。这种设计使得 不仅包含当前句子的信息,还能感知上下文。 检索过程:用户查询经过编码得到
,然后计算 与所有 的内积相似度,选取相似度最高的 k 个句子作为检索结果。由于 Landmark Embedding 是在完整上下文中编码的,因此能够保留更丰富的语义信息。 滑动窗口处理:当文档长度超过模型的最大上下文窗口时,采用滑动窗口的方式分段编码。每个窗口独立计算 Landmark Embedding,最后将所有窗口的结果合并用于检索。
位置感知目标函数(Position-Aware Objective)
LMK 通过对比学习得到,对用户 query 有用的信息往往聚集在连续的句子中
连续信息的处理:长文本中的信息通常是由多个连续句子共同传达的。不同于传统的"正样本"赋予等同权重的做法,Landmark Embedding 为每个句子赋予不同的权重,权重值随着句子位置的接近性而递增,以确保文本信息的完整性。
位置权重:通过引入一个基于位置的权重函数,将句子的重要性随着它离信息"边界"的远近调整,使最靠近边界的句子得到更高的权重。具体地,目标函数会通过对比学习方式训练 Landmark 嵌入,使得查询与其相关句子的嵌入相似度更高。
多阶段学习
提出了一个多阶段的训练方法,利用不同的数据来源来提升 Landmark Embedding 的嵌入质量,使 1)基本的语义区分能力、2)上下文表示能力,这两种能力能够在适当的训练数据之上逐步建立。LE 初始化为通用的句子级别的 embedding model,然后,将其增强为上下文表示模型,可以为其包含的句子生成判别嵌入。包含以下三个阶段:
远程监督。首先,利用 MS MARCO 中的成对训练数据,基于此模型可以初始化为一个基本的句子嵌入器。在这里,Landmark Embedding 采取特殊形式,只有一个单独的 LMK 附加在答案上下文的末尾:
。第一阶段训练遵循密集检索的基本训练形式,为每个 query 检索 15 个难负样本和批次内负样本。 弱监督。对成对训练数据进行了简单修改,模型被训练以在长上下文中生成有区分性的句子嵌入。具体来说,随机打乱不同用户 query 的答案,并将它们合并为一个伪长文档。第 i 个答案的嵌入可以生成为:
。第二阶段仍然依赖于批次内负样本,其中来自其他答案的 Landmark 嵌入 被用作负样本。 微调。利用合成数据进行最终阶段的微调。在这一步中,利用维基百科(Foundation)的真实长文档。对于每个长文档,随机采样一系列文本跨度,通过提示 LLM 生成伪查询。此外,它可能与真实世界数据分布不同。因此,只有少量合成数据被生成用于最终训练阶段。然而,得益于前两个阶段建立的基本能力,Landmark Embedding 在适度微调后可以实现卓越性能。
与其他分块方法对比
下表总结了 Landmark Embedding 与传统分块方法的对比:
| 方法 | 分块策略 | 优点 | 缺点 |
|---|---|---|---|
| 固定长度分块 | 按固定 token 数切分 | 实现简单,计算高效 | 破坏语义完整性,边界处信息丢失 |
| 重叠分块 | 相邻块有重叠部分 | 缓解边界问题,保留部分上下文 | 增加存储和计算开销 |
| 语义分块 | 基于语义相似度切分 | 保持语义连贯性 | 计算成本高,依赖 embedding 质量 |
| 递归字符分块 | 按分隔符层级切分 | 保持文档结构 | 可能切分过细或过粗 |
| Landmark Embedding | 无分块,直接编码完整上下文 | 保留完整语义,无需切分 | 编码成本高,需要滑动窗口处理长文档 |
核心差异分析
语义完整性:传统分块方法在切分时不可避免地会破坏语义完整性,即使使用重叠分块也无法完全避免。Landmark Embedding 通过在完整上下文中编码,保留了所有句子的语义信息。
信息检索精度:由于 Landmark Embedding 能够感知上下文,其检索精度通常高于传统分块方法,特别是在需要理解复杂语义关系的场景中。
计算成本:Landmark Embedding 需要在完整上下文中编码,计算成本较高。而传统分块方法只需要对每个块独立编码,可以并行处理。
存储需求:Landmark Embedding 需要存储所有句子的嵌入向量,存储需求与文档长度成正比。传统分块方法的存储需求取决于块的数量和大小。
适用场景分析
适合使用 Chunking-free RAG 的场景
长文档检索:当文档长度超过模型最大上下文窗口时,传统分块方法可能丢失关键信息。Landmark Embedding 通过滑动窗口编码,能够处理任意长度的文档。
需要理解复杂语义关系的场景:例如法律文档、学术论文、技术手册等,这些文档中的信息往往跨越多个段落,需要理解上下文关系才能准确检索。
多跳推理任务:当查询需要关联多个文档片段才能回答时,Landmark Embedding 的上下文感知能力能够提供更准确的检索结果。
对检索精度要求高的场景:例如医疗诊断、金融分析等高风险领域,需要确保检索结果的完整性和准确性。
不适合使用 Chunking-free RAG 的场景
计算资源受限的场景:Landmark Embedding 需要在完整上下文中编码,计算成本较高。如果计算资源有限,传统分块方法可能是更好的选择。
实时性要求高的场景:由于编码成本高,Landmark Embedding 可能无法满足实时检索的需求。
文档结构简单的场景:如果文档结构简单,信息集中,传统分块方法可能已经足够。
小规模数据集:对于小规模数据集,传统分块方法的性能已经足够,不需要使用更复杂的 Landmark Embedding。
实际应用案例
案例 1:法律文档检索
在法律领域,文档通常很长且包含复杂的逻辑关系。使用 Landmark Embedding 可以:
- 保持法律条款的完整性,避免因分块导致的语义断裂
- 提高相关条款的检索精度,确保法律推理的准确性
- 支持多跳推理,例如从一个条款关联到相关的判例
案例 2:学术论文检索
学术论文通常包含引言、方法、实验、结论等多个部分,信息分布在不同段落。Landmark Embedding 可以:
- 捕获论文的整体结构和逻辑关系
- 支持基于研究问题、方法、结论的多维度检索
- 提高跨论文引用和关联分析的准确性
案例 3:技术文档检索
技术文档通常包含大量的代码示例、配置说明、故障排除等内容。Landmark Embedding 可以:
- 保持代码和说明文字的关联性
- 支持基于功能、问题类型、解决方案的检索
- 提高技术支持和问题诊断的效率
实现建议
模型选择:建议使用支持长上下文的编码器模型,如 Longformer、BigBird 或专门针对长文本优化的 BGE 模型。
滑动窗口设置:根据文档长度和模型最大上下文窗口设置合适的窗口大小和步长。通常建议窗口重叠 20%-30% 以保持上下文连续性。
Landmark 标记训练:需要使用对比学习方法训练 Landmark 标记,使其能够聚合句子的语义信息。建议使用难负样本和批次内负样本进行训练。
索引优化:由于 Landmark Embedding 需要存储所有句子的嵌入向量,建议使用高效的向量索引(如 HNSW)来加速检索。
混合检索:可以将 Landmark Embedding 与传统分块方法结合使用,例如先用 Landmark Embedding 进行粗筛,再用传统方法进行精排,以平衡精度和效率。