GraphRAG
RAG 为 LLM 提供了从某些数据源检索到的信息,作为其生成答案的依据。也就是将根据上下文相关信息进行检索,基于检索到的知识指导 LLM 进行生成。
RAG 能一定程度上缓解大模型面临的问题:
幻觉:通过检索相关的文档,减少生成内容幻觉,提供更多的可解释性。
知识实时更新:RAG 模型的非参数化记忆可以轻松更新,以反映当下世界的知识变化,无需对模型重新训练。
数据隐私:RAG 通过本地化部署私有知识库,限定模型仅访问相关内部数据,从而有效防止敏感信息外泄。
但是基于 RAG 的大模型应用面临的问题:
平面检索:RAG 将每个文档作为一个独立的信息。想象一下,阅读单独的书页,却不知道它们之间是如何连接的。这种方法错过了不同信息片段之间更深层次的关系。
语境缺陷:如果不理解关系和语境,人工智能可能会提供不连贯的反应。这就像有一个图书管理员,他知道在哪里可以找到书,但是却不知道书中的故事之间的联系。
可伸缩性问题:随着信息量的增长,寻找正确的文档变得越来越慢,也越来越复杂,就像试图在不断扩展的库中找到一本特定的书一样。
全局语义理解:RAG 在对大型数据集进行总结和理解的任务上表现不佳,难以把握全局语义。
GraphRAG 不使用非结构化的文本,而是利用知识图谱,利用图结构捕捉数据中的实体、关系及复杂依赖,从而更高效地检索相关信息并生成准确答案。GraphRAG 的一大特色是利用图机器学习算法针对数据集进行语义聚合和层次化分析,因而可以回答一些相对高层级的抽象或总结性问题,这一点恰好是常规 RAG 系统的短板(例如:用户提问一个问题,需要全局搜索整个数据集,而不是搜索相似性片段,在这种场景下 RAG 性能比较差)。
GraphRAG 基本步骤为:
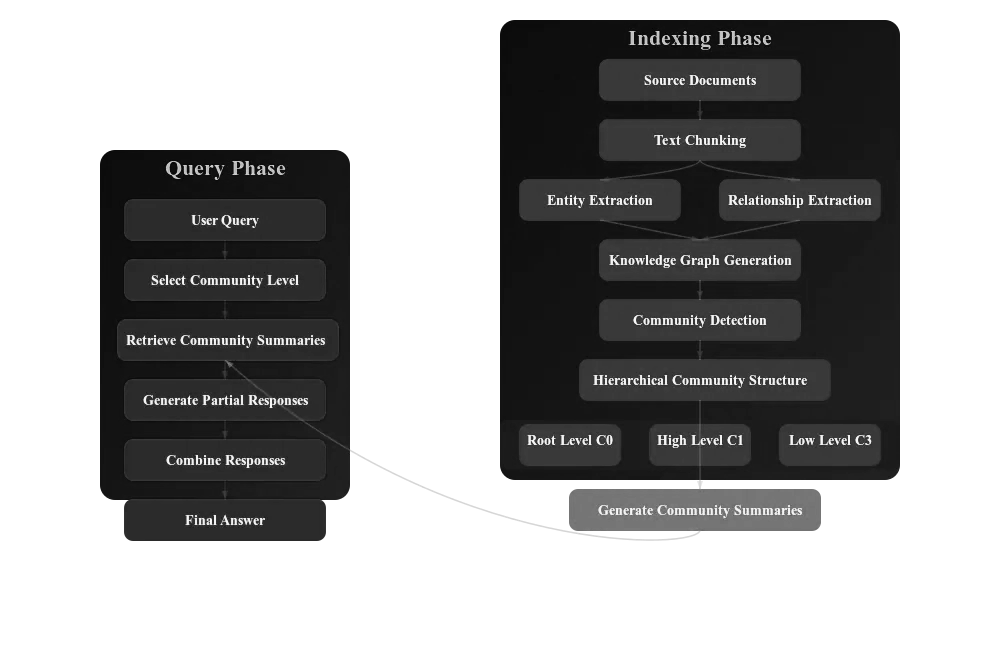
将输入语料库切分为一系列文本单元,利用 LLM 创建对源数据中所有实体和关系的引用,然后使用这些引用来创建 LLM 生成的知识图谱。
通过图算法检测社区结构(进行创建自下而上的聚类),构建分层结构。使用 LLM 为每个社区生成自然语言摘要,帮助全面理解数据集。
在用户查询时,可以进行局部搜索或者全局搜索。
GraphRAG 总结
基于图的检索:传统的 RAG 方法使用向量相似性进行检索,而 GraphRAG 引入了知识图谱来捕捉实体、关系及其他重要元数据,从而更有效地进行推理。
层次聚类:GraphRAG 使用 Leiden 等技术进行层次聚类,将实体及其关系进行组织,提供更丰富的上下文信息来处理复杂的查询。
多模式查询:支持多种查询模式:
全局搜索:通过利用社区摘要来进行全局性推理。
局部搜索:通过扩展相关实体的邻居和关联概念来进行具体实体的推理。
DRIFT 搜索:结合局部搜索和社区信息,提供更准确和相关的答案。
Prompt 调优:GraphRAG 通过 prompt 调优能显著提升性能,通过描述图拓扑结构、限制检索范围、注入结构化信息等方式,能实现精准的图语义对齐、检索效率提高和更高质量的回复。
知识图谱构建详细流程
第一步:输入文档处理
GraphRAG 将一组文本文档的 Chunking 作为输入,这些输入一般存储在图数据库中。
常见的图数据库:
Neo4j:最流行的属性图数据库,具有"无索引邻接"特性,每个顶点维护着指向其邻接顶点的直接引用,图导航操作代价与图大小无关,仅与图的遍历范围成正比。支持 ACID 事务,适用于多种应用场景,包括社交网络、推荐系统、生物信息学等。
ArangoDB:多模型数据库,支持图、文档和键值存储。允许在单个数据库中同时使用多种数据模型,适用于各种不同的应用场景。
TigerGraph:高性能的分布式图数据库,支持复杂的图查询和分析,以及内置的图算法库。适用于处理大规模的图数据。
第二步:实体和语义关系提取
LLM 用于从输入文档中自动提取实体(人、地点、概念)以及它们之间的关系。这是使用命名实体识别(NER)和关系提取等自然语言技术完成的。
实体提取的关键步骤:
定义实体类型:根据应用场景定义需要提取的实体类型,如人名、地名、组织名、概念等。
上下文感知提取:利用 LLM 的上下文理解能力,从文本中识别实体及其属性。
关系识别:识别实体之间的语义关系,如"工作于"、"位于"、"属于"等。
实体消歧:处理同名实体的不同指代,确保同一实体在图中只有一个节点。
第三步:知识图谱生成
利用提取的实体和关系构造知识图谱数据结构,通过知识融合对数据进行逻辑归属和冗杂/错误过滤。
知识融合的关键技术:
实体对齐:将不同来源但指代同一实体的节点合并。
关系验证:验证提取的关系是否符合逻辑和常识。
冲突检测:检测并解决知识图谱中的矛盾信息。
置信度评估:为每个实体和关系分配置信度分数。
第四步:分层社区检测
使用图算法(例如 Leiden),找出紧密相关的实体群体形成的社区。这些社区代表了跨越多个文档的主题或主题。社区按等级组织,高层次社区包含低层次的子社区。
Leiden 算法的优势:
高效性:能够在大规模图上快速检测社区。
层次化:能够检测多层次的社区结构。
质量保证:相比 Louvain 算法,Leiden 算法能够保证检测到的社区是连通的。
第五步:生成信息摘要
利用 LLM 为每个社区生成摘要,包括社区中的实体、关系。此外再将社区的分层结构保留在分层摘要中。
摘要生成的要点:
关键信息提取:从社区中提取最重要的实体和关系。
层次化表达:在不同层次的摘要中提供不同粒度的信息。
可读性优化:确保生成的摘要易于理解,适合人类阅读。
GraphRAG 与传统 RAG 对比
| 特性 | 传统 RAG | GraphRAG |
|---|---|---|
| 数据表示 | 非结构化文本块 | 结构化知识图谱 |
| 检索方式 | 向量相似度检索 | 图遍历 + 向量检索 |
| 关系理解 | 有限,依赖上下文窗口 | 完整,通过图结构捕捉 |
| 全局推理 | 较弱,需要大量文本 | 较强,通过社区摘要支持 |
| 多跳推理 | 困难,需要多次检索 | 自然,通过图路径实现 |
| 可解释性 | 中等,依赖检索结果 | 较高,通过图结构展示 |
| 构建成本 | 较低 | 较高,需要图谱构建 |
| 维护成本 | 较低 | 较高,需要图谱更新 |
核心差异分析
信息组织方式:传统 RAG 将信息分散在独立的文本块中,而 GraphRAG 通过知识图谱将信息组织成结构化的图结构,能够更好地捕捉实体之间的关系。
推理能力:传统 RAG 主要依赖向量相似度进行检索,推理能力有限。GraphRAG 通过图结构支持多跳推理和复杂关系查询。
全局理解:传统 RAG 难以对大型数据集进行全局理解,而 GraphRAG 通过层次化社区检测和摘要生成,能够提供全局视角。
可扩展性:传统 RAG 在数据量增长时性能下降明显,而 GraphRAG 通过图结构的层次化组织,能够更好地处理大规模数据。
实际应用案例
案例 1:企业知识管理
场景:大型企业需要管理大量的内部文档、报告和知识资产。
GraphRAG 的应用:
实体提取:从文档中提取员工、部门、项目、技术等实体。
关系构建:建立员工-部门、项目-技术、文档-作者等关系。
社区检测:识别技术领域、项目组、知识领域等社区。
查询支持:
- 局部搜索:"张三参与了哪些项目?"
- 全局搜索:"公司主要的技术方向有哪些?"
案例 2:医疗知识图谱
场景:医疗领域需要整合大量的医学文献、病例和知识。
GraphRAG 的应用:
实体提取:提取疾病、症状、药物、治疗方法等实体。
关系构建:建立疾病-症状、药物-适应症、治疗-效果等关系。
社区检测:识别疾病类型、治疗领域、研究方向等社区。
查询支持:
- 局部搜索:"糖尿病有哪些并发症?"
- 全局搜索:"当前癌症治疗的主要方法有哪些?"
案例 3:法律文档分析
场景:法律领域需要分析大量的法律文档、判例和法规。
GraphRAG 的应用:
实体提取:提取法律条文、判例、当事人、法律概念等实体。
关系构建:建立判例-法条、当事人-案件、概念-定义等关系。
社区检测:识别法律领域、案件类型、法律原则等社区。
查询支持:
- 局部搜索:"关于知识产权的判例有哪些?"
- 全局搜索:"近年来劳动法的主要变化是什么?"
检索增强生成
主要有两种检索方式:
局部检索:局部搜索旨在理解和回答关于特定实体及其相关概念的详细问题。将用户查询与社区摘要进行匹配,以查找最相关的社区,向该实体的邻居(即相关实体)扩展搜索。
全局检索:全局搜索是为了理解和回答关于整个文档集的综合性问题,如"数据中的前 N 个主题是什么?"这类需要跨文档聚合信息的查询。利用知识图的分层结构对整个数据集进行搜索,以查找回答查询所需的特定实体、关系和信息。这包括了遍历知识图谱和组合来自多个社区的信息,可以提供全面的响应。
局部检索
当用户提出关于特定实体(如人名、地点、组织等)的问题时,应该采用局部搜索的方法,如下图所示:
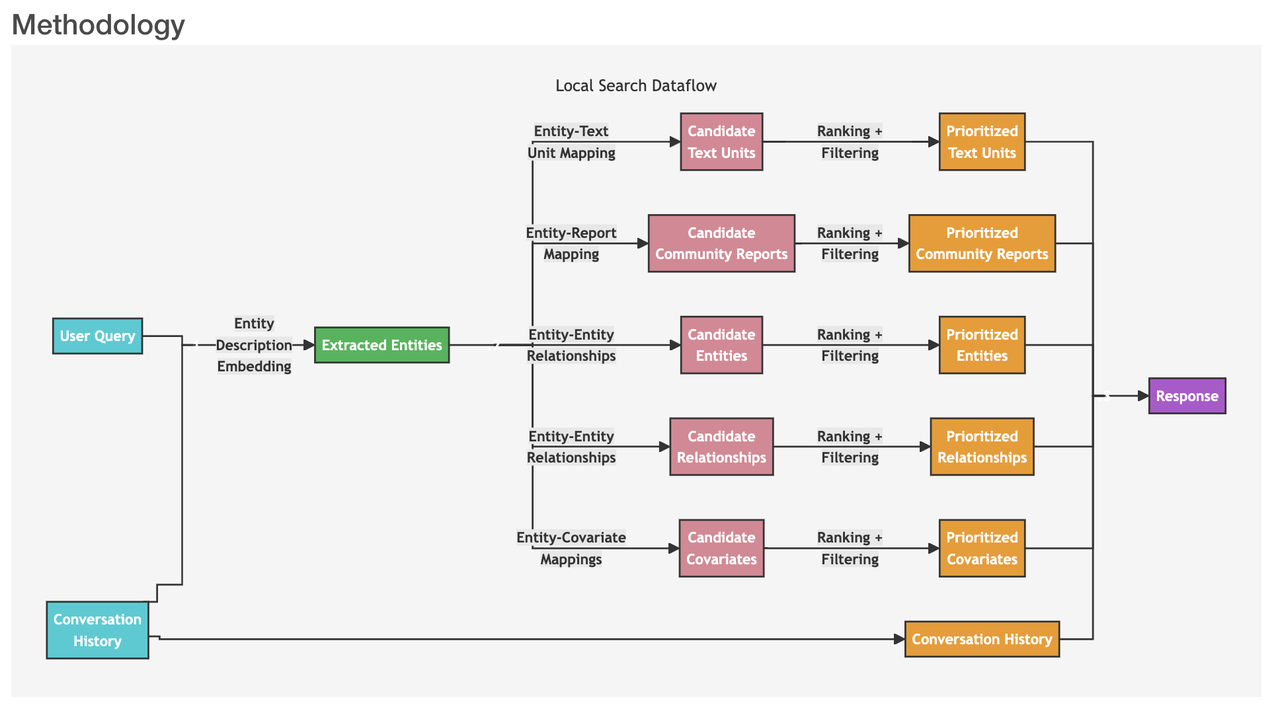
用户查询:首先,系统接收用户查询,这可能是一个简单的问题或更复杂的查询。
搜索相似实体:系统从知识图中识别出与用户输入语义相关的一组实体。这些实体作为进入知识图谱的入口点。这一步骤中使用像 Milvus 这样的向量数据库进行文本相似性搜索。
实体-文本单元映射:提取的文本单元被映射到相应的实体,移除原始的文本信息。
实体-关系提取:这一步提取关于实体及其相应关系的特定信息。
实体-协变量(Covariate)映射:这一步将实体映射到它们的协变量,这可能包括统计数据或其他相关属性。
实体-社区摘要映射:社区摘要被整合到搜索结果中,纳入一些全局信息。
利用对话历史:如果有对话历史,系统使用对话历史来更好地理解用户的意图和上下文。
生成响应:最后,系统根据前几步生成的经过过滤和排序的数据生成并响应用户查询。
全局检索
参考:https://arxiv.org/pdf/2404.16130
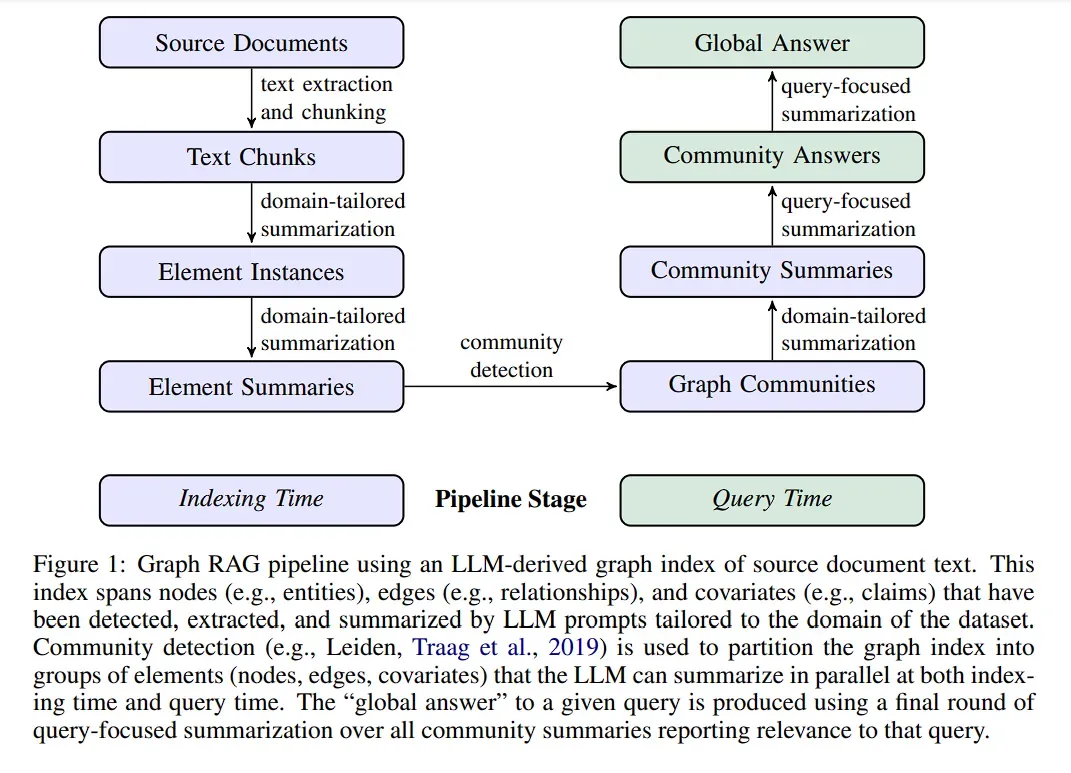
针对用户提出的需要全局搜索整个数据集的全局性问题,提出了一种基于 GraphRAG 的回复方法,大致分为 6 个步骤:
- 源文档 → 文本块
粒度:将源文档的文本分割成块。
权衡:更长的块需要更少的 LLM 调用,但可能因为较长的上下文窗口而降低召回率。
示例:在 HotPotQA 数据集上,600 token 的块大小提取的实体引用几乎是 2400 token 块大小的两倍。
- 文本块 → 元素实例
目标:从文本块中识别和提取图节点和边。使用 LLM 提示识别实体和关系,输出限定元组。
定制化:可以通过为 LLM 提供少量领域特定的示例来定制提示,以适应不同的知识领域(如科学、医学、法律等)。
协变量提取:支持二级提取提示,用于提取与提取的节点实例相关的其他协变量,如实体相关的声明、主题、对象、类型、描述、源文本范围以及开始和结束日期。
多轮提取:在不牺牲块大小的情况下检测到更多实体。
- 元素实例 → 元素摘要
摘要:LLM 抽象并总结文本中的实体、关系和声明。
处理重复:LLM 可能无法始终以统一的格式提取同一实体的引用,可能会产生重复的实体元素。但由于检测到密切相关的实体及其摘要,加上 LLM 可以理解多种名称变体对应的共同实体,只要这些变体与一组密切相关的实体有足够的连接性,整体方法就能够应对这种变体。
- 元素摘要 → 图社区
图建模:创建一个无向加权图,其中节点是实体,边是关系。
社区检测:使用 Leiden 算法将图分割成层次化社区,将具有较强内部连接的节点划分为社区,实现高效的全局摘要。
- 图社区 → 社区摘要
摘要创建:为每个社区生成报告式摘要。
实用性:摘要有助于理解数据集的全局结构和语义,辅助回答全局查询。用户可以浏览不同层级的社区摘要,寻找感兴趣的一般主题,然后深入到较低层级的摘要以获取更多细节。
- 社区摘要 → 社区回答 → 全局回答
查询社区摘要:首先定位用户查询需要哪一层级的社区摘要进行回复,然后在这一层级检索相关的社区摘要。
社区摘要处理:社区摘要被随机打乱并划分为预设大小的块。这确保相关信息分布在各个块中,而不是集中(并可能丢失)在单个上下文窗口中。
社区回答映射:为每一块社区摘要并行生成社区回答,利用 LLM 生成有用程度分数。
归纳全局回答:按照有用程度得分降序对中间社区答案进行排序,并迭代地添加到新的上下文窗口中,直到达到 token 限制。
参考:
GraphRAG 的主要优点
结构化知识表示:GraphRAG 使用知识图谱来表示信息、捕获实体、关系和层次结构,更准确的理解上下文语义。
高效处理:在知识图谱中将数据预处理可以降低计算成本,并且与传统的 RAG 方法相比,可以更快地检索。
多方面查询处理:GraphRAG 可以通过综合来自知识图谱多个部分的相关信息来处理复杂的多方面查询。
可解释性:与大模型的黑盒输出相比,GraphRAG 中的结构化知识表示提供了更高的透明度和可解释性。检索支持 global_search、local_search 和 drift_search。