Transformer
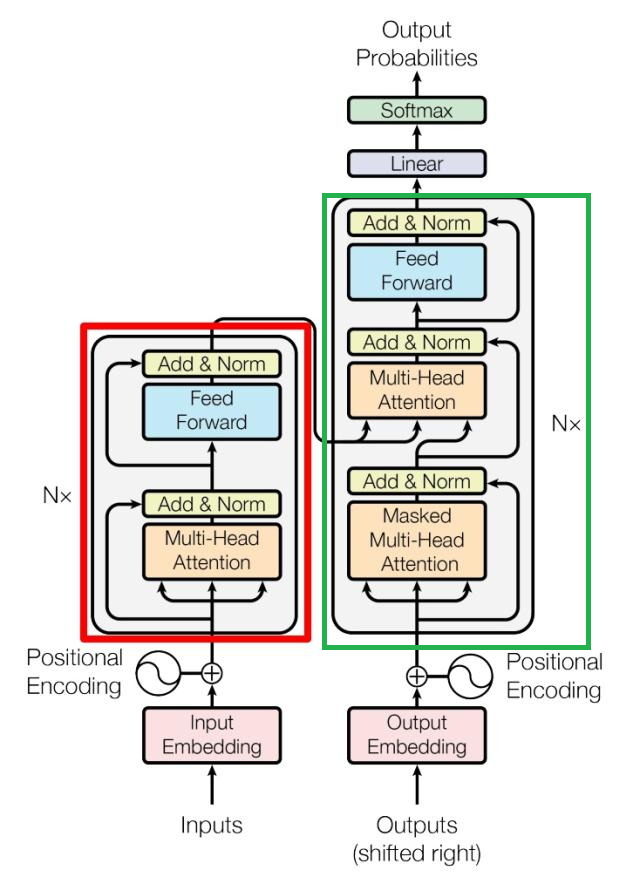
Embedding
由输入的嵌入向量(Embedding)和位置编码(Positional Encoding)相加得到,后面的文章详细介绍。
输入的嵌入向量可以通过Word2Vec、BERT、OpenAI Embedding API等方式获取,目的是将文本映射到连续的向量空间(把文本变成模型能处理的向量)。
位置编码是为了捕捉输入中Token的顺序信息,常用的有RoPE、绝对位置编码等。
Encoder
上图中红色部分就是编码器(Encoder),由多头注意力(Multi-Head Attention)、残差连接与归一化(Add & Norm)、前馈网络(Feed Forward)、残差连接与归一化(Add & Norm)组成。输入为矩阵
Add & Norm
包含两次层归一化(Layer Normalization,对每个样本的特征维度进行标准化,可以加速训练过程和提高模型的泛化性能)和残差连接操作,分别是:
这种归一化方式被称为后归一化(Post-Norm),本文后面会详细介绍。
Feed Forward
两个简单的全连接层。
Decoder
上图中绿色部分就是解码器(Decoder),其中第一个多头注意力使用了掩码矩阵。第二个多头注意力使用了交叉注意力(Cross-Attention)。Decoder之后会有一个Softmax层用来预测下一个Token。
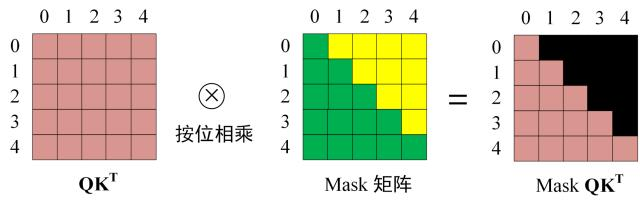
掩码矩阵
如下图所示,解码过程中会将之前预测的输出作为当前预测的输入。通过掩码矩阵可以防止第

掩码矩阵在自注意力的Softmax之前使用。
其中
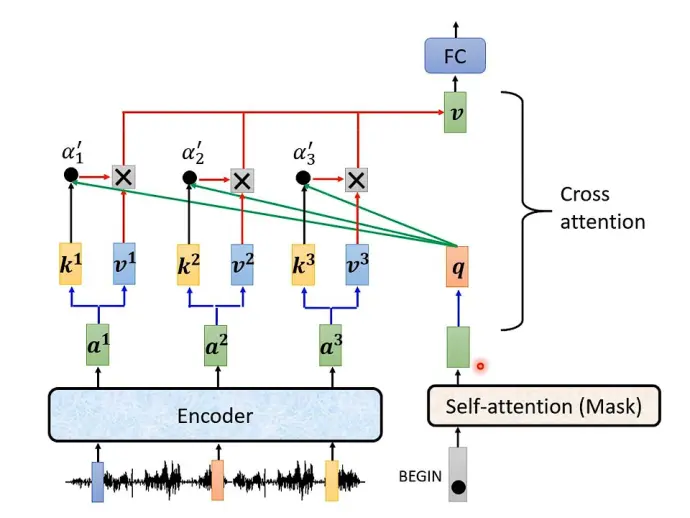
Cross-Attention
这里的K和V矩阵是由Encoder的编码信息矩阵计算得到的,Q是由上一个Decoder Block计算得到的。
Softmax
由于之前使用了掩码矩阵,第
Transformer 总结
优点:支持并行计算(RNN需要顺序计算),具有捕获长距离语义依赖的能力,已衍生出大量后续模型。
缺点:计算复杂度为
,需要大量数据进行训练。
Transformer 原始架构的局限性
尽管Transformer在自然语言处理领域取得了巨大成功,但原始架构仍存在一些局限性:
计算复杂度高:自注意力机制的计算复杂度为
,其中 是序列长度。对于长序列,计算和内存开销会急剧增加,这限制了Transformer处理超长文本的能力。 位置编码的局限性:原始Transformer使用固定的三角位置编码,虽然能编码绝对位置信息,但在处理训练时未见过的序列长度时,泛化能力有限。
缺乏递归结构:与RNN不同,Transformer没有递归结构,需要通过位置编码显式地注入位置信息,且对位置信息的建模能力有限。
对大规模数据的依赖:Transformer需要大量数据进行训练,在小数据集上容易过拟合,性能不如传统的序列模型。
注意力头的冗余:多头注意力机制中,部分注意力头可能学习到相似的模式,存在一定的参数冗余。
这些局限性推动了后续研究,如稀疏注意力机制、线性注意力、Flash Attention等改进方案的提出。
Pre-Norm 和 Post-Norm 的区别
前归一化(Pre-Norm)和后归一化(Post-Norm)分别指将归一化操作放在残差连接之前和之后。
先说结论:Pre-Norm结构往往更容易训练,但最终效果通常不如Post-Norm。参考文献是《Understanding the Difficulty of Training Transformers》和《RealFormer: Transformer Likes Residual Attention》。
这里指的是Post-Norm在最优设置下的性能优于Pre-Norm,而不是在相同配置下。因为Post-Norm更难训练,需要一些额外的操作(比如需要添加学习率Warmup)。
Pre-Norm 效果为什么更差
对于Pre-Norm,迭代可以得到:
其中每一项都是同一量级的(苏剑林认为这一说法并不准确,这是一个基于直觉的判断,即为了追求稳定的梯度,认为每一层的更新量都比较接近),那么有
这个公式的意思是由于
Post-Norm 为什么更难训练
先说结论:Post-Norm严重削弱了残差的恒等分支,所以反而失去了残差"易于训练"的优点,通常要Warmup并设置足够小的学习率才能使它收敛。
假设初始状态的
迭代下去就得到了:
残差的本意是为了给前面的层添加一个快速通道,保障梯度快速回传。而Post-Norm削弱了这个快速通道,残差名存实亡,容易导致梯度消失,难以训练。
梯度消失指的是在深度网络的反向传播阶段,梯度在从输出层向输入层传播的过程中逐渐变小,最终趋于接近零。前面的层梯度较小乃至不更新,会导致后面层的输入质量变低,从而导致模型准确率降低。为了缓解梯度消失,可以采用残差连接,补上一个梯度为常数的项。
梯度消失在微调模型时是优点。因为微调希望优先调整后面的层,而前面的层少调整,避免破坏预训练学到的知识。梯度消失正好对前面的层调整较弱。所以,预训练好的Post-Norm模型,往往比Pre-Norm模型有更好的微调效果。
为什么Adam优化器比SGD优化器更容易收敛(受梯度消失影响小)? Adam优化器的更新公式如下:
- 梯度的一阶动量(动量)估计:
这里,
- 梯度的二阶动量(方差)估计:
- 偏差修正:由于动量和方差在初始时刻可能较小,需要进行偏差修正:
- 参数更新:使用修正后的动量和方差计算每个参数的更新值:
Adam每一轮的更新量是
量级的,理论上只要梯度的绝对值大于随机误差,那么对应的参数都会有常数量级的更新量;而SGD的更新量正比于梯度,梯度过小会导致参数不更新,因此受梯度消失影响更严重。
与之对比的Pre-Norm保留了完整的快速通道:
Warmup 学习率对 Post-Norm 的作用
Warmup学习率指学习率随着轮数逐渐增长到目标学习率。如果不进行Warmup学习率,那么后面的层学习会很快,但由于前面的层梯度消失,学习的并不好,导致后面的层是建立在糟糕的输入上的。这会导致模型陷入局部最优,最坏的情况下,前面的层学习效果过于差,后面层每轮的更新变成了随机常数,Loss发散成NaN。
而使用Warmup,就留给模型足够多的时间进行"预热"。在这个过程中,主要是抑制了后面的层的学习速度,并且给了前面的层更多的优化时间,以促进每个层的同步优化。
DeepNorm
对输入乘上一个
总结:
Post-Norm:适合较浅的Transformer网络,或者任务不太复杂时,它可以取得更好的准确性。
Pre-Norm:对于深层Transformer模型,它的梯度更加稳定,收敛性有保障,因此通常在深度模型中表现得更好。