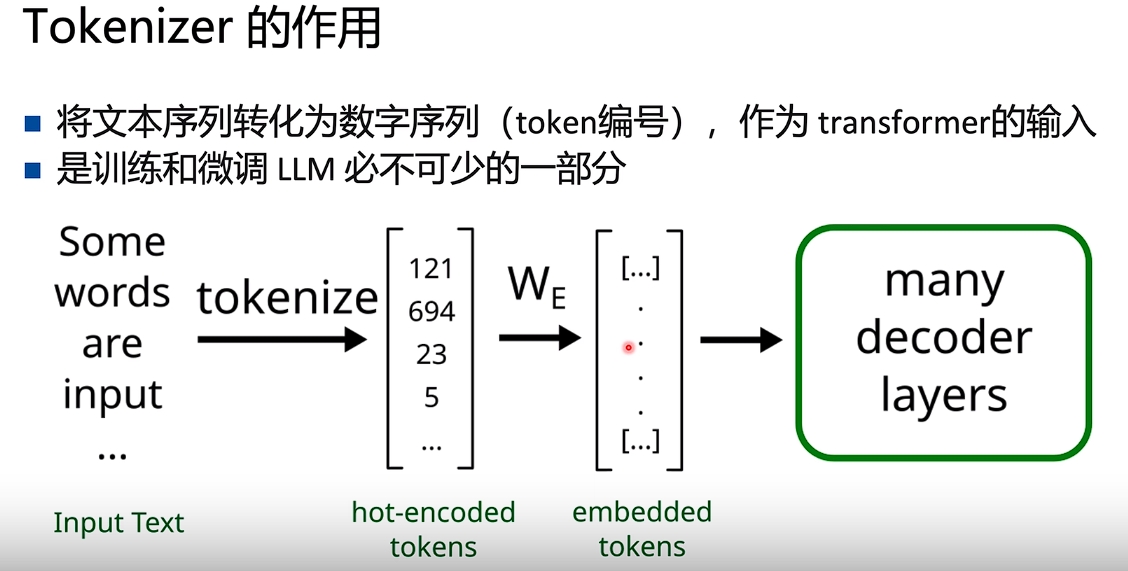
Tokenizer
这一节中的图都出自《大语言模型LLM基础之Tokenizer完全介绍》,视频讲解的非常清晰。
Word-based Tokenizer
将文本划分为一个个词。缺点是将相同意思的词划为不同的Token,且词表巨大。巨大的词表意味着需要学习巨大的嵌入矩阵(Embedding Matrix),会导致空间复杂度和时间复杂度的大幅增加。
Character-based Tokenizer
将文本划分为一个个字符。缺点是相较于Word-based,信息量很低,模型性能差,且Token序列很长。
Subword-based Tokenizer
以上两者的折中。对于高频的字符串片段(比如常用词、词根、词缀),将其作为一个整体的Token,而不是再继续细分为更小的单位。具体分为以下几种:
Byte Pair Encoding Tokenizer(BPE)
BPE的输入是一个语料库(Corpus),以英文举例包括很多的单词。初始的词表采用Character-based Tokenizer的词表。迭代地进行词频统计和词表合并两步,直到达到合并次数上限。
词频统计:统计词中相邻Token共同出现的词频。
词表合并:将最常出现的相邻Token加入到词表中。
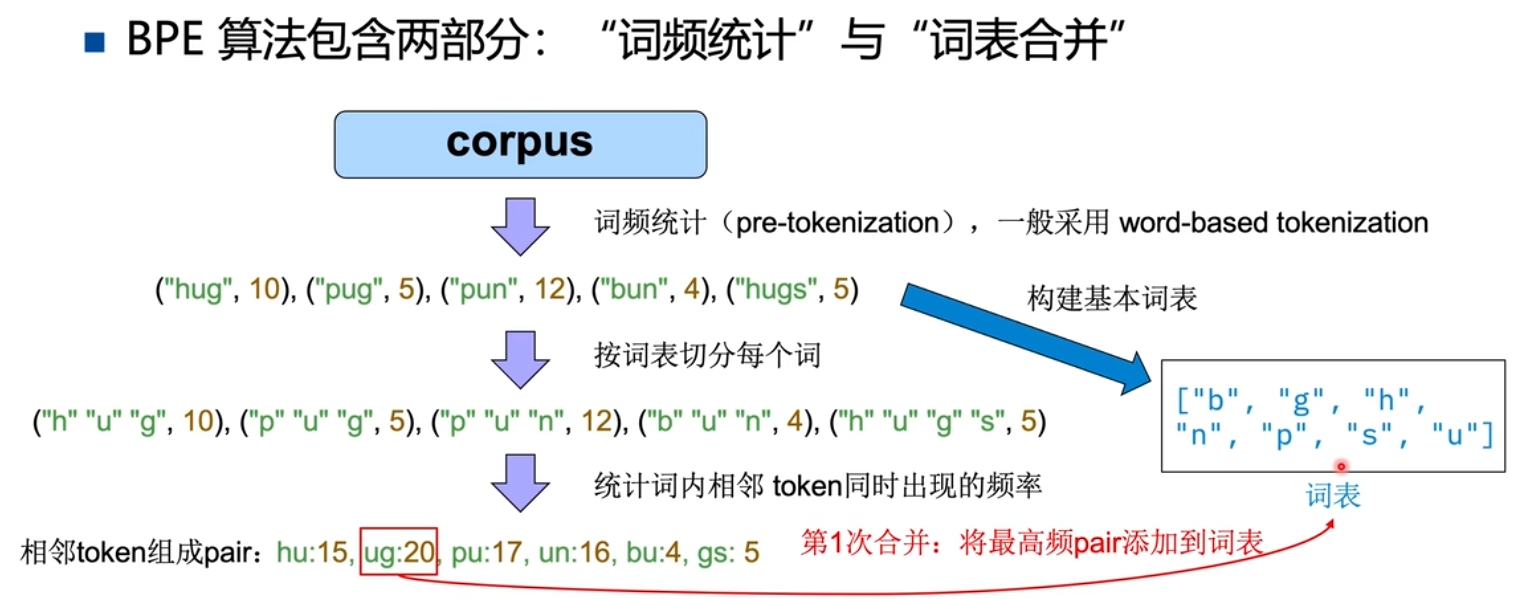

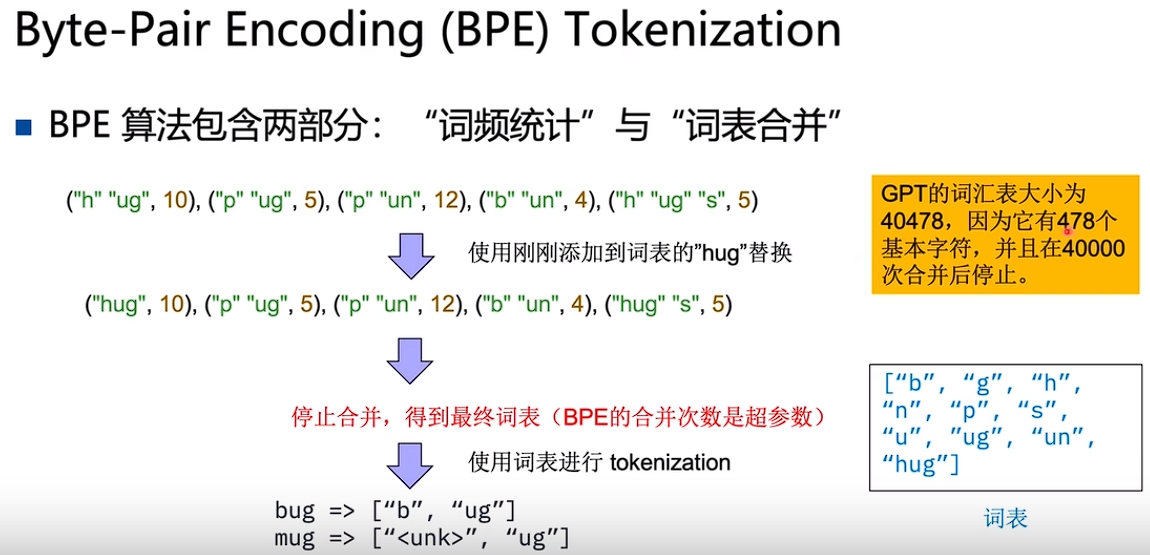
BPE 训练过程详解
BPE的训练过程是一个迭代合并的过程,具体步骤如下:
步骤1:初始化词表
将语料库中的所有单词拆分为单个字符,并在每个单词末尾添加特殊标记(如</w>)表示词边界。初始词表包含所有出现过的字符。
步骤2:统计相邻Token对的频率
遍历语料库中所有单词,统计每一对相邻Token共同出现的次数。例如:
| 单词 | 频率 | 分解形式 |
|---|---|---|
| "low" | 5 | l o w </w> |
| "lower" | 2 | l o w e r </w> |
| "newest" | 6 | n e w e s t </w> |
| "widest" | 3 | w i d e s t </w> |
统计相邻对频率:
(e, s): 9次(s, t): 9次(es, t): 9次(如果es已合并)- ...
步骤3:合并最高频的Token对
将频率最高的相邻Token对合并为一个新的Token,加入词表。例如合并(e, s)为es。
步骤4:更新语料库的分解形式
用新的合并结果更新语料库中所有单词的分解形式。
步骤5:重复步骤2-4
重复进行频率统计和合并操作,直到达到预设的合并次数或词表大小。
BPE训练伪代码:
输入: 语料库 corpus, 合并次数 num_merges
输出: 最终词表 vocabulary
vocabulary = {所有单个字符 + 特殊标记}
for i in range(num_merges):
统计所有相邻Token对的频率
找到频率最高的Token对 (token_a, token_b)
将 (token_a, token_b) 合并为新Token "token_a + token_b"
将新Token加入vocabulary
更新corpus中所有单词的分解形式
return vocabularyByte-level BPE(BBPE)
BPE的缺点在于其初始词表很大。BBPE用两个字节表示一个Token的Unicode码,将Unicode码作为基础Token。

BBPE 与 BPE 的对比
| 特性 | BPE | BBPE |
|---|---|---|
| 基础单元 | 字符(Character) | 字节(Byte) |
| 初始词表大小 | 较大(取决于字符集) | 固定为256(所有字节值) |
| 多语言支持 | 需要为每种语言准备字符集 | 天然支持所有语言 |
| 未登录词处理 | 需要特殊处理 | 可以用字节序列表示任何字符 |
| 词表压缩率 | 较高 | 较低(相同文本需要更多Token) |
| 实现复杂度 | 较简单 | 需要处理字节到字符的映射 |
| 典型应用 | GPT-2、RoBERTa | GPT-4、LLaMA、Qwen |
BBPE的优势:
- 零依赖:不依赖于任何特定的字符集,可以在任何文本上运行
- 确定性:任何输入都能产生唯一确定的Token序列
- 鲁棒性:对拼写错误、罕见字符等有更好的处理能力
BBPE的劣势:
- Token数量较多:相同文本被拆分为更多的Token,增加了序列长度
- 语义粒度较粗:基础单元是字节而非有意义的字符,可能影响语义理解
WordPiece Tokenization
与BPE的思路基本一样,区别在于合并的规则不同。BPE选择频率最高的Token对进行合并,而WordPiece选择使语言模型似然最大化的Token对进行合并。

Unigram Tokenization
先初始化一个很大的词表(包含字母、所有子词)。
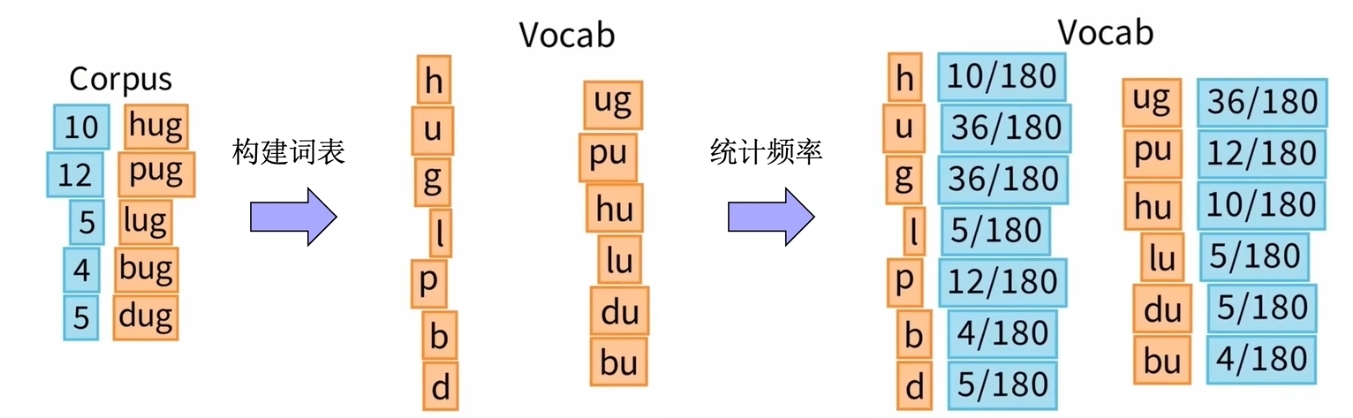
Unigram算法假设每个词都是独立出现的,因此整个单词出现的概率就是其中每个词概率的乘积。计算出语料库中每个单词出现的最大概率,作为该单词的分词方式。
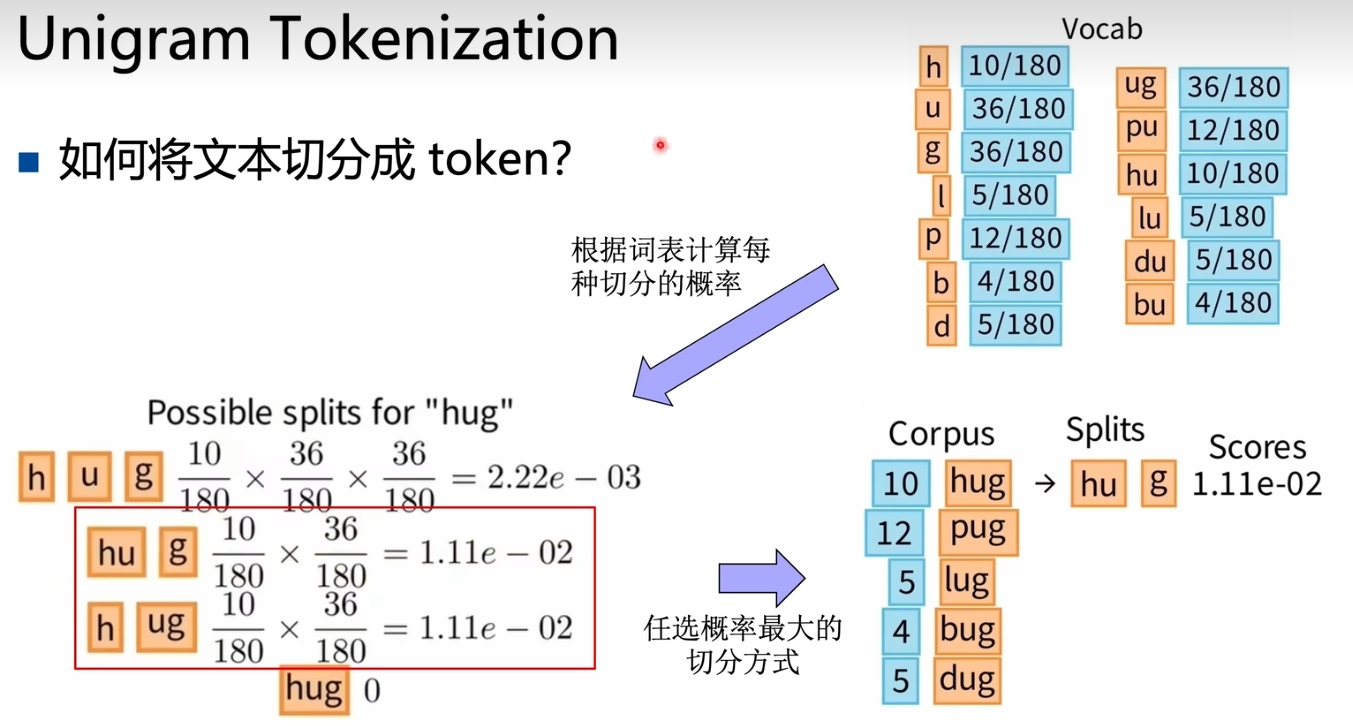
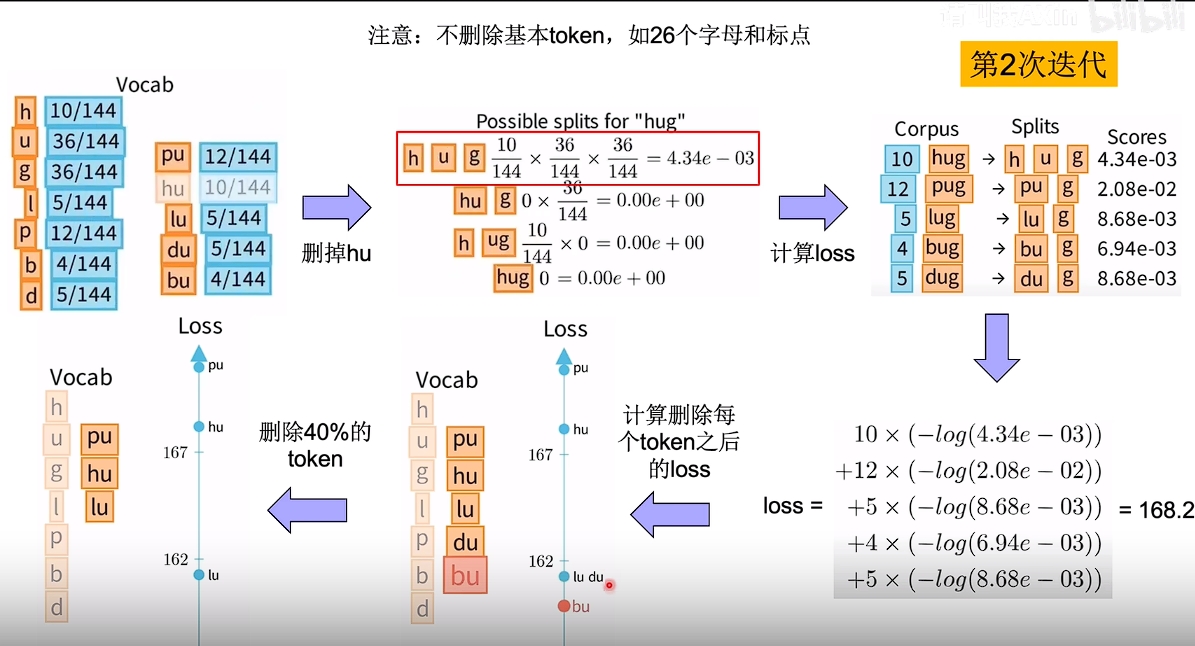
每一轮删除一个子词,该子词满足删除后负对数似然变得最小。如果每个子词删除后负对数似然大小一样,则随机删除一个。删去
SentencePiece(使用BBPE或Unigram)

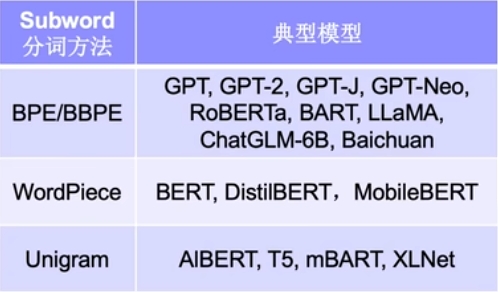
各分词方法对应的常见模型
最后总结一下以上分词方法对应的常见模型:
Tokenizer 对模型性能的影响
Tokenizer的选择和设计对大语言模型的性能有着深远的影响:
1. 词表大小的影响
词表过小:会导致文本被拆分为过多的Token,序列长度增加,计算复杂度上升(自注意力的复杂度为
),同时可能丢失语义信息。 词表过大会:导致嵌入矩阵参数量增加,低频词的向量表示训练不充分,且Softmax层的计算开销增大。
2. 分词粒度的影响
过粗的分词(如Word-based):词表巨大,OOV(Out-of-Vocabulary)问题严重,无法处理新词。
过细的分词(如Character-based):序列过长,语义信息分散,模型难以捕捉完整的语义单元。
适中的分词(如BPE):在词表大小和语义完整性之间取得平衡。
3. 多语言支持
- 不同语言的字符集差异很大,使用BPE可能需要为每种语言单独训练。
- BBPE通过字节级别操作,天然支持多语言,是目前多语言模型的首选。
4. 对下游任务的影响
- 文本分类:分词粒度影响特征提取,过细的分词可能增加噪声。
- 机器翻译:分词粒度影响翻译质量,需要保持源语言和目标语言的分词一致性。
- 文本生成:分词方式影响生成文本的流畅度和多样性。
5. 实际案例
- GPT系列:使用BPE,词表大小从GPT-2的50,257增长到GPT-4的约100,000。
- BERT:使用WordPiece,词表大小为30,522。
- LLaMA:使用SentencePiece和BBPE,词表大小为32,000。
- Qwen:使用BBPE,词表大小为151,643,支持多语言。
在transformers库中使用Tokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
sen = "弱小的我也有大梦想!"
inputs = tokenizer(sen, padding="max_length", max_length=15)
print(inputs)
# {
# "input_ids": [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
# "token_type_ids": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# "attention_mask": [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
# }
# input_ids 对应embedding,
# token_type_ids表示属于第几个句子,
# attention_mask表示embedding中哪部分是真实有效的。