位置编码
卷积具有局部性,天然地注意到了元素之间的相对位置。而基于自注意力的Transformer模型则对位置不敏感,因此必须要把元素的位置信息加入到嵌入向量中。
绝对位置编码
绝对位置编码直接将位置信息加到文本的嵌入向量中,被早期的BERT、GPT-2等模型中使用。绝对位置编码又可以分为可学习的和固定的两种。
可学习绝对位置编码:直接对不同的位置随机初始化一个位置嵌入(Position Embedding),加到文本的嵌入向量上输入给模型,作为参数进行训练。这种方法引入了大量的可学习参数,需要大量的数据才能训练。
固定的绝对位置编码:代表是《Attention is All You Need》论文中的三角位置编码。
位置
其中
这里的相对位置关系指的是两个Token之间的,而绝对位置编码中每个位置的编码是固定的。相对位置编码则直接考虑两个Token之间的相对位置。
证明:需要用到三角公式,定义
为了计算
和 之间的距离,可以通过计算它们之间的内积:
可以看到
和 之间的内积随着相对距离的增加而减小,符合文本中Token之间一般距离越远关系越弱的原理。但是由于相对距离的对称性,三角位置编码无法区分方向,即 与 和 与 之间的距离是一样的。实现三角位置编码的代码如下:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout) # 初始化dropout层
# 计算位置编码并将其存储在pe张量中
pe = torch.zeros(max_len, d_model) # 创建一个max_len x d_model的全零张量
# 生成0到max_len-1的整数序列,并添加一个维度
position = torch.arange(0, max_len).unsqueeze(1)
# 计算div_term,用于缩放不同位置的正弦和余弦函数
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
# 对于d_model的偶数索引,使用正弦函数;对于奇数索引,使用余弦函数
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 在第一个维度添加一个维度,以便进行批处理
# 定义前向传播函数
def forward(self, x):
# 将输入x与对应的位置编码相加
x = x + self.pe[:, : x.size(1)]
# 应用dropout层并返回结果
return self.dropout(x)总结:绝对位置编码实现简单,存在以下缺点:
尽管能包含一定的相对位置信息,但是这种信息仅仅保存在位置编码内部,在计算自注意力时,这种位置信息就被破坏了。
一个Token的位置编码是什么由其在句子中的绝对位置决定,但是真正重要的往往不是绝对位置,而是它与其他Token之间的关系。
对输入的长度敏感,一旦输入变化则需要重新调整。
相对位置编码
相对位置编码将两个Token的相对位置信息添加到对应的注意力值中。
ALiBi(Attention with Linear Biases)
在计算注意力时,对前边位置的分数进行惩罚,如图所示:
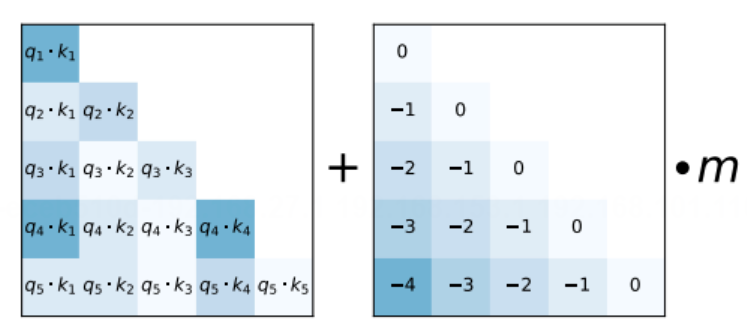
传统的绝对位置编码在训练时会为每个位置分配一个固定的向量,模型可能会过度拟合这些特定长度的模式。而ALiBi通过在注意力分数计算中直接使用线性偏置,减少了模型对特定序列长度的依赖,从而提高了对未见过的序列长度的泛化能力。
ALiBi的位置偏差随距离线性增长,这种设计让模型在处理不同长度的序列时,可以自然地根据距离调整注意力权重,无需显式学习位置编码的复杂周期性结构。
由于线性偏置的引入直接与序列中元素的位置相关,没有固定大小的编码矩阵限制,理论上模型可以更容易地处理任意长度的序列,从而展现出良好的长度外推性能。
通过直接在注意力分数上施加与距离相关的线性惩罚,ALiBi鼓励模型关注更近的位置,同时不完全排除远处的依赖,从而在一定程度上平衡了局部和全局依赖的学习,这对于处理长序列尤其有利。
XLNET
三角位置编码在计算注意力时的表示如下:
从绝对位置编码出发:
XLNET将
T5
(11)式中的每一项可以理解为"输入-输入"、"输入-位置"、"位置-输入"、"位置-位置"四项注意力的组合。由于输入信息与位置信息应该是独立(解耦)的,它们不应该有过多的交互,所以"输入-位置"、"位置-输入"两项注意力可以删掉,"位置-位置"实际上是一个依赖于
此外,通过固定的桶函数
DeBERTa
与T5相反,扔掉"位置-位置"一项,只保留剩下三项。通过
DeBERTa在Softmax时校正系数为
旋转位置编码 RoPE
RoPE实现了绝对位置编码和相对位置编码的统一,它通过绝对位置编码的形式,实现了相对位置编码的效果。
RoPE将输入序列的位置信息通过旋转操作嵌入到自注意力的计算中,为不同位置的Token分配差异化旋转角度,使位置信息与Token语义特征深度融合,显著增强模型对长序列的建模能力及对相对位置关系的敏感度。RoPE的频率(base)是可学习的,在自注意力公式中结合了明确的相对位置依赖性。
RoPE保持了序列长度的灵活性、随相对距离的增加而衰减的Token间依赖性。其原理如下图,针对词嵌入维度

从内积的角度推导
其中
二维向量可以表示成虚数形式:
由欧拉公式
再写成向量形式:
代入到内积中:
对于多维的旋转位置编码,可以简化为以下形式:
可以看到矩阵中有很多元素是0,如果用矩阵乘法,其实有很多计算是无用的。
结合代码来看,在ChatGLM中,因为内积计算与顺序无关,巧妙地将所有负数和正数分开。

从公式的角度推导
要计算
由欧拉公式
不要复数,只保留实数部分:
总结下RoPE的流程:首先计算得到
那么对于
得到的注意力随
改进:xPOS
RoPE能扩展到任意长度,但其外推性能较差:虽然RoPE可以拓展到任意长度,但对于语言建模等生成任务,无法在测试长序列性能时,维持其在训练长度序列上的表现。xPos在旋转的基础上,在旋转角度向量的每个维度上都包含了独特的指数衰减因子,以及Blockwise Causal Attention,让模型忽略相距较远的语义: