Memory
正文开始之前先放一个吴恩达老师对Agent的理解图,其中的很多方法已经介绍过了:
任务分解是指借助LLM将任务拆解为若干个子任务,并依次对每个子任务进行规划。可以分为先分解后规划(HuggingGPT,plan and solve)和边分解边规划(COT,react,pal)两个思路
多方案选择是指大型语言模型深入"思考",针对特定任务提出多种可能的方案。接着,利用针对性的任务搜索机制,从中挑选一个最合适的方案来实施。例如ToT,GoT,LAT
外部模块辅助规划。该策略专门设计用于引入外部规划器,以增强规划过程的效率和计划的可行性,同时大型语言模型主要负责将任务规范化。分为符号规划器(LLM+P)和神经规划器(利用强化学习训练深度学习模型,作为决策模型)
反思与优化。这种策略着重于通过自我反思和细节完善来增强规划能力。它激励大型语言模型Agent应用在遭遇失败后进行深入反思,并据此优化规划方案。例如Reflexion,critic
记忆增强规划。该策略通过引入一个附加的记忆组件来提升规划能力,该组件中存储了各种宝贵信息,包括基本常识、历史经验、领域专业知识等。在进行规划时,这些信息会被调取出来,充当辅助提示,以增强规划的效果。分为RAG记忆(即接下来要介绍的Memory)和嵌入式记忆(将RAG知识通过微调嵌入到模型参数里)
记忆模块是智能体存储内部日志的关键组成部分,负责存储过去的思考、行动、观察以及与用户的互动。
短期记忆关注于当前情境的上下文信息,是短暂且有限的,通常通过上下文窗口限制的学习实现。
长期记忆储存智能体的历史行为和思考,通过外部向量存储实现,以便快速检索重要信息。
混合记忆 -通过整合短期和长期记忆,不仅优化了智能体对当前情境的理解,还加强了对过去经验的利用,从而提高了其长期推理和经验积累的能力。
长期记忆存储到外部存储器中,最常见的做法是将记忆的embedding存储到支持快速的最大内积搜索(MIPS,Maximum Inner Product Search)的向量存储数据库中。不只是文本,图像、音视频等非结构化数据也可以存储为结构化向量,降低了存储和计算的成本,同时加速了检索效率。
参考:A Survey on the Memory Mechanism of Large Language Model based Agents
基本概念
任务:agent要实现的目标,例如订一个机票,下面用
表示一个问题。 环境:agent为了完成任务需要与环境交互,环境包含了可能改变agent决策的上下文信息。
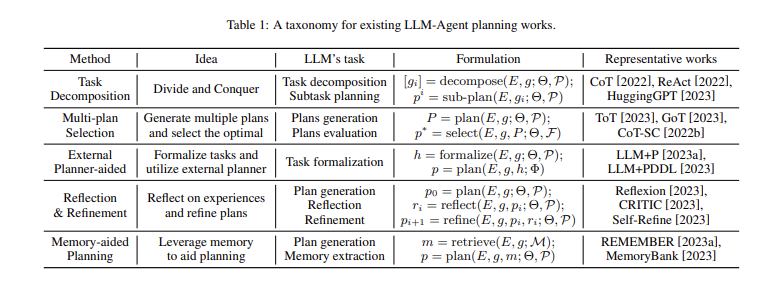
trial:agent采取行动,并从环境获得行动的反馈,基于此反馈再采取行动,循环持续直到任务完成,这一过程被称为trial。一个长度为T的trial可以表示为 $ξ_T = {a_1, o_1, ...,.a_T, o_T} $,其中
分别是行动和环境。每一轮agent与环境的交互被称为一个step。每个任务可能有多个trial,即为了完成一个任务可能做很多尝试。 memory:狭义上的memory指同一个trial中的历史信息。给定一系列任务
,对于任务 在第t步时,广义的memory来自3个方面: 1)同一个trial之前的历史信息,记为:
2)任务k之前的任务的trial,以及任务k之前尝试的trial(记为k'):
3)外部知识,比如通过RAG查询到的知识,表示为:
Memory-based Agent
agent在与环境交互的过程可以分为3个阶段。
1)智能体从环境中感知信息,并将其存储到记忆中。
2)智能体对存储的信息进行处理,使其更加可用;
3)智能体根据处理后的记忆信息采取下一步行动。
对应了三个agent memory的三个操作:
写记忆:此操作旨在将从环境的原始观察结果投射到实际存储的记忆内容中,这些内容更具信息量和简洁。这一操作可以表示为
,W表示映射函数, 是最终写入memory的内容,可以以自然语言的形式或者参数化的形式。 记忆管理:使得记忆信息更加高效,例如总结高级的概括性概念以使得agent更具有泛化性,合并相似信息以降低冗余性,忘记不重要信息避免造成负面影响。这一操作表示为
, 是第t轮的记忆, 表示之前处理过的记忆,P是迭代处理存储的记忆信息的函数。对于广义的记忆,这一操作会跨trial跨任务执行,并且会随着外部知识的变化而执行。 读记忆:从memory获取信息以采取下一次行动,
, 表示下一个行动的上下文,R是计算相似度的函数, 表示计算得到的最相似的记忆内容,会被加入下一轮agent的prompt中。
基于以上操作,就可以得到agent做决策的统一表示,下图展示了agent完成一个任务的工作流程。
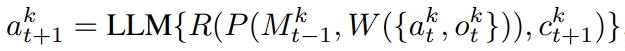
为什么要使用 Memory-based Agent
从认知心理学角度:对于人类的认知来说,记忆重要的模块,agent想要替代人类完成一些任务,就要表现的像人类,为agent设置代理模块。
从自我进化角度:在完成任务的过程中,agent也需要在与环境交互时自我进化。记忆能帮助agent积累经验、探索更多的环境、抽象出概括性信息以增强泛化性。
从agent应用角度:在很多应用中记忆是不可取代的,例如chatgpt、虚拟角色。
如何实现 Memory-based Agent
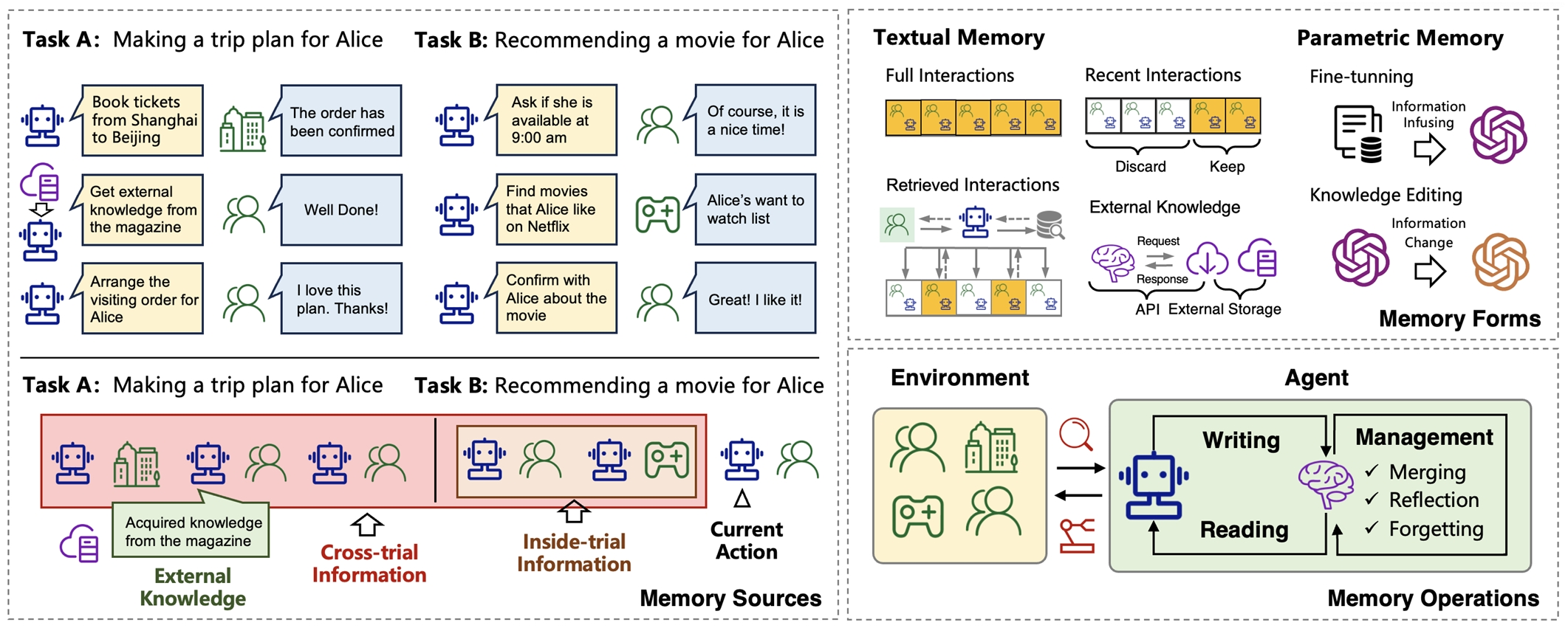
记忆来源
如之前介绍的,memory来源主要包含3部分:同一个trial,跨trial跨任务,外部知识。前两部分都来自agent与环境交互,外部知识来自任务以外的环境。代表工作有这些:

同一个trial:同一个trial中的历史步骤是最相关最有信息量的信息,与agent的任务高度相关。这部分信息不仅包括代理环境交互,还包含交互上下文,例如时间和位置信息。
跨trial跨任务:在环境中多次试验所积累的信息也是记忆的重要组成部分,通常包括成功和失败的操作及其见解,例如失败的原因、成功的常见行动模式等,基于过去的经验,agent可以根据整个过程的整体反馈调整其行为。代表工作是Planning篇介绍的Reflexion。同一个trial的可以视为短期记忆,跨trial跨任务的则是长期记忆。
外部知识:根据任务需求实时动态访问各种工具的 API 来获取,例如搜索维基百科,扩展agent的知识边界。代表工作是Planning篇介绍的React。
记忆形式
记忆一般有两种形式:文本和参数化形式。代表工作有这些:
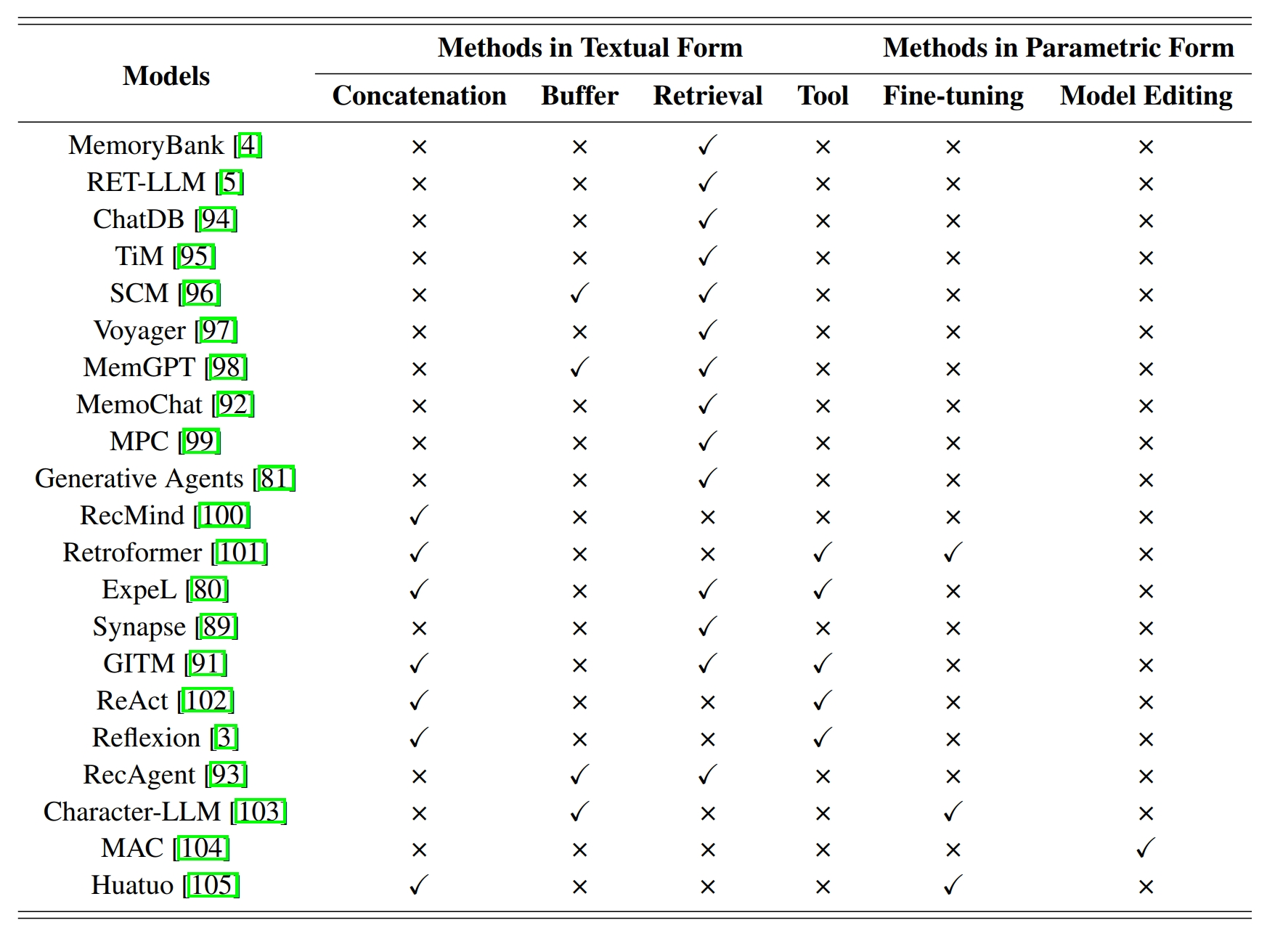
文本形式是目前表示记忆内容的主流方法,具有可解释性更好、更容易实现、读写效率更快的特点。过去的研究主要分为4个方向:
(1)完整的agent-环境交互:计算成本和推理时间都会大幅增加,并且推理容易不鲁棒,因为文本在长上下文中的位置会极大地影响它们的利用率,长上下文提示中的记忆不能得到平等和稳定的处理。
(2)最近的agent-环境交互:会遗忘遥远的记忆,对于长期任务可能导致关键信息缺失,并且如何确定缓存窗口也比较困难。
(3)检索到的agent-环境交互:根据记忆内容的相关性进行检索,在记忆读取时,会为每个记忆条目计算匹配分数,并选取 top-K 条目。在记忆写入时生成embedding作为记忆的索引,以辅助信息检索。检索需要额外的计算成本。
(4)外部知识:通过调用工具获取外部知识(如维基百科),可能会涉及检索、重排等多个计算过程,如何将外部知识和内部决策过程融合值得研究。
参数化形式的记忆存储在模型的参数中,不受 LLM 上下文长度限制的限制。现有方法主要分为两类:微调方法和记忆编辑方法。
(1)微调方法:通过有监督微调将外部知识整合到代理的记忆中,能显著提升模型在特定领域的能力。只能应用在离线场景。面临着微调通用的问题,灾难性遗忘,过拟合,需要大量数据,计算成本高等。
(2)记忆编辑方法:直接修改Transformer模型的权重, 以实现对模型记忆的精确编辑。记忆编辑只针对需要修改的事实,更适合小规模的记忆调整,适合在线场景。
对比文本形式记忆和参数化形式记忆:
有效性:文本记忆存储有关agent与环境交互的原始信息,这些信息更全面、更详细。然而,它受到 prompt中token上限的限制,这使得agent难以存储大量信息。相比之下,参数记忆不受提示长度的限制,但在将文本转换为参数时可能会遭受信息丢失,复杂的记忆训练会带来额外的挑战。
效率:对于文本记忆,每次 LLM 推理都需要将记忆整合到上下文提示中,这会导致更高的成本和更长的处理时间。相比之下,对于参数记忆,信息可以集成到 LLM 的参数中,从而消除了这些上下文的额外成本。然而,将参数记忆写入模型的需要额外的成本,但文本记忆更容易写作,尤其是对于少量数据。简而言之,文本记忆在写作方面更有效率,而参数记忆在阅读方面更有效率。
可解释性:文本记忆通常比参数记忆更易于解释,因为自然语言是人类理解的最自然、最直接的策略,而参数记忆通常以潜在空间表示。然而,这种可解释性是以信息密度为代价的。这是因为文本记忆中的单词序列以离散空间表示,而离散空间不像参数记忆中的连续空间那样密集。
总之文本记忆更适合对话和特定上下文的场景,并且上下文内容不太多。参数化记忆适合有大量知识需要写入模型记忆的场景。
记忆操作
如上文所述,对记忆的操作主要有写记忆,记忆管理,读记忆。
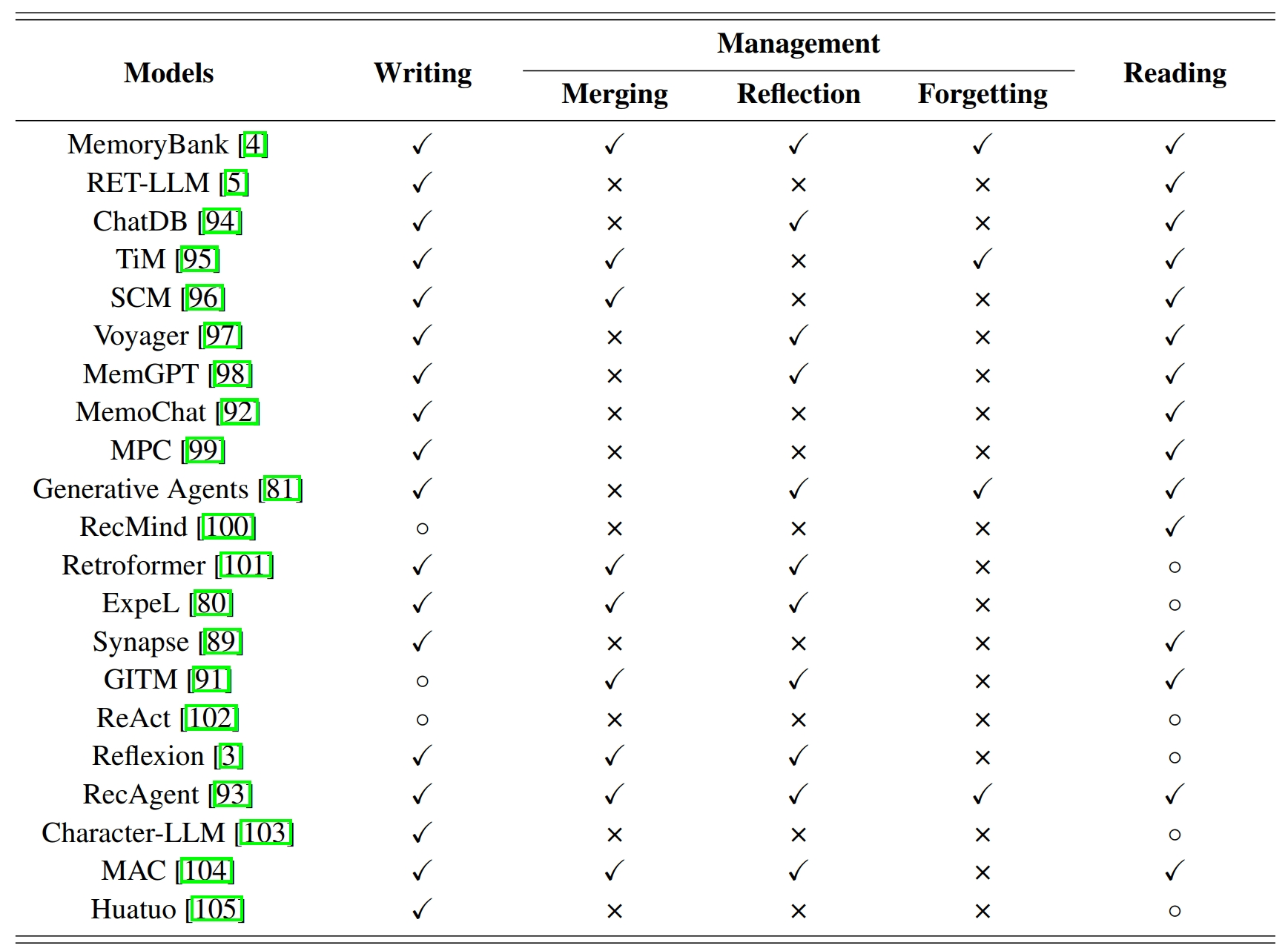
写记忆:识别哪些信息应该写入记忆至关重要,并且应该对原始信息中的噪声进行处理。此外,环境可能会提供各种形式的反馈,如何从这些反馈中提取有效信息(可能涉及多模态)也至关重要。
记忆管理:通过不断的反思来管理,以生成更高级的记忆,合并多余的记忆条目,并忘记不重要的早期记忆。
读记忆:对于文本形式的记忆,可以采用文本相似度来筛选记忆。而对于参数化的记忆,模型直接用更新后的模型进行推理,这可以视为隐式的阅读过程。
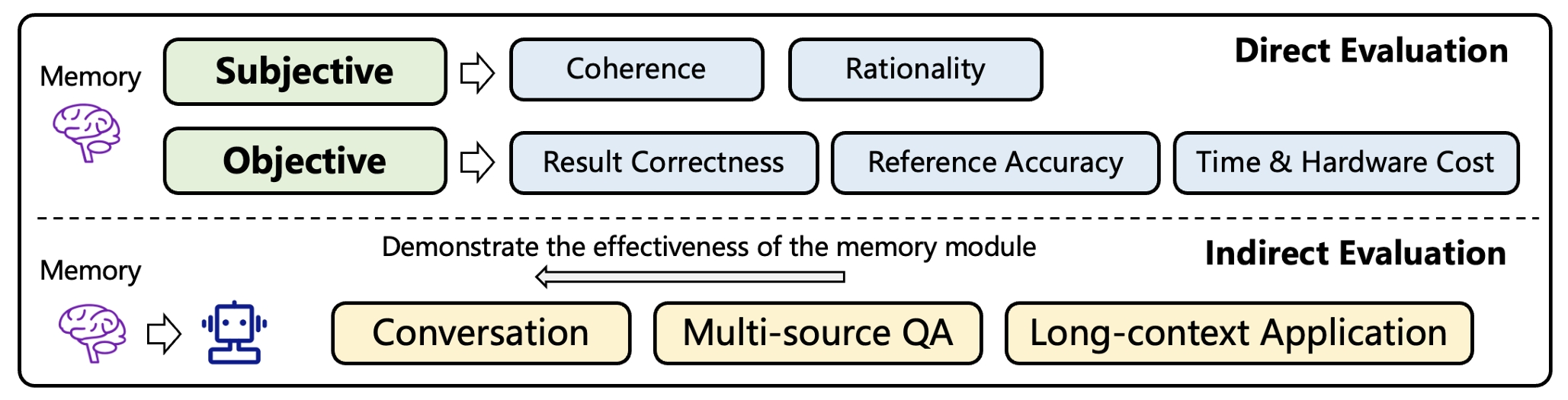
如何评估 Memory-based Agent
本文将评估方法分为两类:(1)直接评估,独立测量记忆模块的能力。(2)间接评估,通过端到端代理任务评估记忆模块。
直接评估:又可以分为人的主观评价和客观指标评价两种
主观评价:主要从回答的连贯性,即检索到的记忆应该与当前情景匹配,以及合理性,即检索到的以及应该包含正确的信息。
客观评价:常见指标包括预测标签准确率,检索到的记忆的F1值,计算和推理时长,GPU占用量
间接评估:如果代理能完成高度依赖记忆的任务,那就证明记忆模块是有效的。代表性任务有:
对话任务:记忆保留与用户对话的上下文,agent的回复应该与上下文一致,不能出现自相矛盾的情况。还可以通过用户的参与度来衡量agent回复的质量和吸引力。
多源问答:综合评估之前提到的多个来源的记忆信息,即同一个trial、跨trial和外部知识,测试agent对不同内容和来源的记忆的整合能力。同时检测多信息源导致的记忆矛盾和知识更新问题。
长文本应用:采用文本形式的记忆会一般都会导致比较长的上下文,需要评估agent能否充分理解长文本,并从中检索出对给定问题有用的内容。
Agent 记忆机制示例
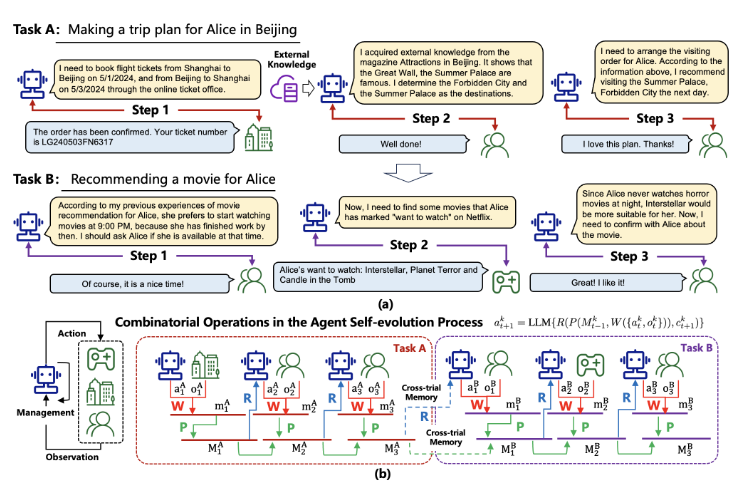
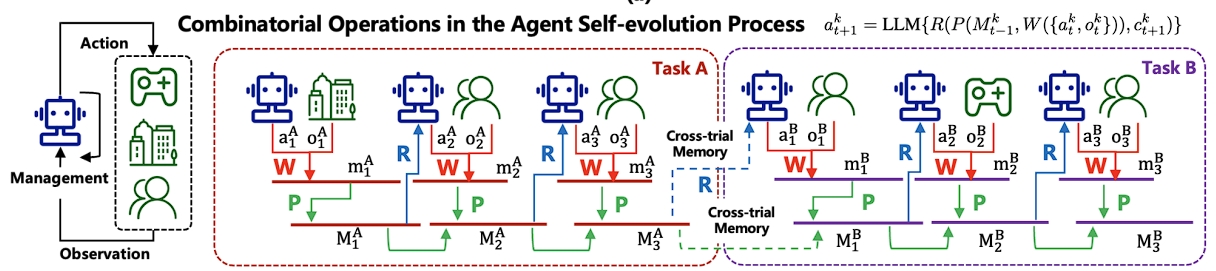
在上图的例子中,Agent有两个任务:
(A) 为Alice在2024年5月1日至5月3日期间在北京制定旅行计划,Agent需要(i) 购买往返机票,(ii) 根据Alice的偏好确定几个景点,(iii) 安排这些景点的参观顺序。
(B) 在2024年5月10日为Alice推荐一部电影,Agent需要(i) 确定Alice有空看电影的时间,(ii) 根据Alice的观看偏好选择一部电影。对于每个任务,在下面展示一个可能的试验:
对于任务(A),试验是:
[步骤 1] Agent:我需要通过在线票务办公室预订2024年5月1日从上海到北京的航班,以及5月3日从北京返回上海的航班。环境(在线票务办公室):订单已确认。出发航班上午9:00起飞,您的票号是EK240501SX9021。返程航班下午4:30起飞,您的票号是LG240503FN6317。请准时到达机场搭乘您的航班。
[步骤 2] Agent:我已经从《北京景点》杂志获取了外部知识。它显示长城、故宫和颐和园都很有名。根据爱丽丝的偏好,我认为她更喜欢古代建筑,所以我确定故宫和颐和园作为目的地。环境(Alice):做得好!
[步骤 3] Agent:现在,我需要为Alice安排参观顺序。根据上面的信息,我建议她一到北京就参观颐和园,因为那里适合整个下午游玩并观看日落。然后,她第二天可以去故宫,这样会给她足够的时间。
最后,她可以在第三天返回上海休息。环境(Alice):我喜欢这个计划。谢谢!
对于任务(B),试验是:
[步骤 1] Agent:根据我以前为Alice推荐电影的经验,她更喜欢在晚上9:00开始看电影,因为那时她已经完成工作。我应该问问Alice那个时间她是否有空。环境(Alice):当然,这是个好时间!
[步骤 2] 智能体:现在,我需要找到一些Alice在Netflix上标记为"想看"的电影。环境(Netflix):Alice的想看列表:《星际穿越》、《恐怖星球》和《鬼吹灯》。
[步骤 3] Agent:由于Alice晚上从不观看恐怖电影,《星际穿越》对她来说更合适。现在,我需要与爱丽丝确认这部电影。环境(Alice):太棒了!我喜欢它!
Langchain 实现 Memory-based Agent
langchain中使用memory的例子(本代码是基于v0.1.7构建的,新版本请自行查看官方InMemorySaver):创建一个简单的自定义代理,该代理可以访问搜索工具并使用 ConversationBufferMemory 类。首先定义搜索工具
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain import OpenAI, LLMChain
from langchain_core.tools import Tool
from langchain_community.utilities import SerpAPIWrapper
from langchain_openai import ChatOpenAI
import os
# 设置API密钥环境变量
os.environ["SERPAPI_API_KEY"] = "Your serpapi key"
# 初始化搜索工具
search = SerpAPIWrapper()
# 加载预定义的工具集
from langchain.agents import load_tools
llm = ChatOpenAI(model=os.environ["LLM_MODELEND"], temperature=0)
tools = load_tools(["serpapi"], llm=llm)接下来定义一个prompt,prompt中的的chat_history需要与ConversationBufferMemory的key对应,存储对话记录。
# 系统指令前缀:定义Agent的基本行为
prefix = """Have a conversation with a human, answering the following questions as
best you can. You have access to the following tools:"""
# 系统指令后缀:包含对话历史占位符和用户输入
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}"""
# 创建提示模板,定义输入变量
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"],
)
# 初始化对话缓冲区内存,用于存储聊天历史
memory = ConversationBufferMemory(memory_key="chat_history")接下来创建一个LLMChain,然后将memory加入到agent中。
# 创建LLM链,将LLM和提示模板绑定
llm_chain = LLMChain(llm=llm, prompt=prompt)
# 创建Agent,绑定工具集
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
# 创建Agent执行器,注入内存模块
agent_chain = AgentExecutor.from_agent_and_tools(
agent=agent, tools=tools, verbose=True, memory=memory
)
# 执行对话,内存会自动记录历史
agent_chain.run(input="How many people live in canada?")
agent_chain.run(input="what is their national anthem called?")langchain中为我们实现了多种记忆,常见的有:
ConversationBufferMemory:所有聊天记录都被存入chat_history中,导致下一轮的prompt很长
ConversationBufferWindowMemory:只保留最近几次人类与AI的互动,只适应短对话。
ConversationSummaryMemory:在回答新问题的时候,对之前的问题进行了总结性的重述,再传递给chat_history 参数,这种基于总结的方法能避免过度使用token,适合长对话。总结由LLM完成,虽然最初使用的 Token 数量较多,但随着对话的进展,汇总方法的增长速度会减慢;并且,总结的过程中并没有区分近期的对话和长期的对话(通常情况下近期的对话更重要)。
ConversationSummaryBufferMemory:总结较早的对话,保留近期的对话原始内容。
Milvus 向量数据库实现记忆
Mem0是一个为AI应用设计的智能记忆层,旨在通过保留用户偏好并随时间不断适应,提供个性化且高效的交互体验。特别适合聊天机器人和AI驱动的工具,Mem0能够创建无缝、上下文感知的体验。
下面将通过介绍Mem0记忆管理的基本操作来做一个Agent持有记忆的简单demo,同时使用Milvus,一个高性能、开源的向量数据库,它能够支持高效的存储和检索。以下代码完成了基础记忆操作,帮助用户使用Mem0和Milvus构建个性化的AI交互。
# 安装依赖包
! pip install mem0ai pymilvus配置 Mem0 与 Milvus
import os
# 设置OpenAI API密钥
os.environ["OPENAI_API_KEY"] = "sk-***"现在,我们可以配置Mem0使用Milvus作为向量存储。
from mem0 import Memory
# 配置Mem0使用Milvus作为向量存储后端
config = {
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "quickstart_mem0_with_milvus",
"embedding_model_dims": "1536",
"url": "./milvus.db", # 使用本地向量数据库用于演示
},
},
"version": "v1.1",
}
# 初始化Memory实例
m = Memory.from_config(config)添加记忆
add函数将非结构化文本作为记忆存储在Milvus中,并将其与特定用户和可选元数据关联。
在这里,将Alice的记忆"working on improving my tennis skills"连同相关metadata一起添加到Milvus中。
# 为用户alice添加一条关于网球爱好记忆
res = m.add(
messages="Working on improving my tennis skills.",
user_id="alice",
metadata={"category": "hobbies"},
)
res输出结果:
{'results': [{'id': '77162018-663b-4dfa-88b1-4f029d6136ab',
'memory': 'Working on improving tennis skills',
'event': 'ADD'}],
'relations': []}搜索记忆
可以使用搜索功能来寻找与用户最相关的记忆。
让我们从为Alice添加另一个记忆开始。
# 为用户alice添加另一条关于考试任务的记忆
new_mem = m.add(
"I have a linear algebra midterm exam on November 20",
user_id="alice",
metadata={"category": "task"},
)现在,调用 get_all 函数并指定 user_id 来验证我们确实为用户alice保存了2条记忆记录。
# 获取用户alice的所有记忆
m.get_all(user_id="alice")输出结果:
{'results': [{'id': '77162018-663b-4dfa-88b1-4f029d6136ab',
'memory': "Working on improving my tennis skills",
'hash': '4c3bc9f87b78418f19df6407bc86e006',
'metadata':{ "category": "hobbies},
'created_at': '2024-11-01T19:33:44.116920-07:00',
'updated_at': '2024-11-01T19:33:47.619857-07:00',
'user_id': 'alice'},
{'id': 'aa8eaa38-74d6-4b58-8207-b881d6d93d02',
'memory': 'Has a linear algebra midterm exam on November 20',
'hash': '575182f46965111ca0a8279c44920ea2',
'metadata': {'category': 'task'},
'created_at': '2024-11-01T19:33:57.271657-07:00',
'updated_at': None,
'user_id': 'alice'}]}可以进行搜索,通过提供查询内容和用户ID来寻找与用户最相关的记忆。默认情况下,使用L2度量(欧几里得距离)来进行相似度搜索,因此,得分越小意味着相似度越高。
# 搜索与alice兴趣相关的记忆
m.search(query="What are Alice's hobbies", user_id="alice")输出结果:
{'results': [{'id': '77162018-663b-4dfa-88b1-4f029d6136ab',
'memory': 'Likes to play tennis on weekends',
'hash': '4c3bc9f87b78418f19df6407bc86e006',
'metadata': None,
'score': 1.2807445526123047,
'created_at': '2024-11-01T19:33:44.116920-07:00',
'updated_at': '2024-11-01T19:33:47.619857-07:00',
'user_id': 'alice'},
{'id': 'aa8eaa38-74d6-4b58-8207-b881d6d93d02',
'memory': 'Has a linear algebra midterm exam on November 20',
'hash': '575182f46965111ca0a8279c44920ea2',
'metadata': {'category': 'task'},
'score': 1.728922724723816,
'created_at': '2024-11-01T19:33:57.271657-07:00',
'updated_at': None,
'user_id': 'alice'}]}