12 计算学习理论
计算学习理论(computational learning theory)是通过“计算”来研究机器学习的理论,简而言之,其目的是分析学习任务的本质,例如:在什么条件下可进行有效的学习,需要多少训练样本能获得较好的精度等,从而为机器学习算法提供理论保证。
假设给定训练集
回归正题,泛化误差指的是学习器在总体上的预测误差,经验误差则是学习器在某个特定数据集
泛化误差:
PAC学习
计算学习理论中,最基本的是概率近似正确 (Probably Approximately Correct, PAC) 学习理论。
从样本空间到标记空间存在着很多的映射,我们将每个映射称之为概念(concept),定义:
- 若概念
对任何样本 满足 ,则称 为目标概念,即最理想的映射,所有的目标概念构成的集合称为“概念类”,用符号 表示; - 给定学习算法
,它所有可能映射/概念的集合称为“假设空间”,由符号 表示。其中单个的概念称为“假设”(hypothesis);
- 若一个算法的假设空间包含目标概念,则称该数据集对该算法是可分(separable)的,亦称一致(consistent)的;
- 若一个算法的假设空间不包含目标概念,则称该数据集对该算法是不可分(non-separable)的,或称不一致(non-consistent)的。
举个简单的例子:对于非线性分布的数据集,若使用一个线性分类器,则该线性分类器对应的假设空间就是空间中所有可能的超平面,显然假设空间不包含该数据集的目标概念,所以称数据集对该学习器是不可分的。给定一个数据集
- 定义12.1 PAC辨识(PAC Identify):对
,所有 和分布 ,若存在学习算法 ,其输出假设 满足$$P(E(h) \le \epsilon) \ge 1 - \delta$$等价于 ,则称学习算法 能从假设空间 中PAC识别概念类 (即目标概念的有效近似)。 - 定义12.2 PAC可学习(PAC Learnable):令
表示从分布 中独立同分布采样得到的样例数目, ,对所有分布 ,若存在学习算法 和多项式函数 ,使得对于任何 , 能从假设空间 中PAC识别概念类 ,则称概念类 对假设空间 而言是PAC可学习的,又是也简称概念类 是PAC可学习的。 - 定义12.3 PAC学习算法(PAC Learning Algorithm):若学习算法
使概念类 为PAC可学习的,且 的运行时间也是多项式函数 ,则称概念类 是高效PAC可学习(efficiently PAC learnable)的,称 为概念类 的PAC学习算法。 - 定义12.4 样本复杂度(Sample Complexity):满足
学习算法 所需的 中最小的 称为学习算法 的样本复杂度。
上述关于PAC的几个定义层层相扣:定义12.1表达的是对于某种学习算法,如果能以一个置信度学得假设满足泛化误差的预设上限,则称该算法能PAC辨识概念类,即该算法的输出假设已经十分地逼近目标概念。定义12.2则将样本数量考虑进来,当样本超过一定数量时,学习算法总是能PAC辨识概念类,则称概念类为PAC可学习的。定义12.3将学习器运行时间也考虑进来,若运行时间为多项式时间,则称PAC学习算法。
显然,PAC学习中的一个关键因素就是假设空间的复杂度,对于某个学习算法,若假设空间越大,则其中包含目标概念的可能性也越大,但同时找到某个具体概念的难度也越大,一般假设空间分为有限假设空间与无限假设空间。
有限假设空间
可分情形
可分或一致的情形指的是:目标概念包含在算法的假设空间中。对于目标概念,在训练集
对于算法的某个输出假设泛化误差大于
,且在数据集上表现完美的概率: 所有这样的假设出现的概率,实际上中间有省略,假设有
个泛化误差大于 的假设, : 令上式不大于
(即目标概念的有效近似),即 ,可得
通过上式可以得知:对于可分情形的有限假设空间,目标概念都是PAC可学习的,即当样本数量满足上述条件之后,在与训练集一致的假设中总是可以在
不可分情形
不可分或不一致的情形指的是:目标概念不存在于假设空间中,这时我们就不能像可分情形时那样从假设空间中寻找目标概念的近似。但当假设空间给定时,必然存一个假设的泛化误差最小,若能找出此假设的有效近似也不失为一个好的目标,这便是不可知学习(agnostic learning)的来源。
定义12.5 不可知PAC可学习(agnostic PAC learn-able):
令
表示从分布 中独立同分布采样得到的样例数目, ,对所有分布 ,若存在学习算法 和多项式函数 ,使得对于任何 , 能从假设空间 中输出满足下式的假设 :$$P\left(E(h)-\min _{h' \in H} E(h') \le \epsilon\right) \ge 1-\delta$$则称假设空间 是不可知PAC可学习的。(即以置信度的概率找到假设空间泛化误差最小的假设的有效近似)
这时候便要用到Hoeffding不等式,以下给出单个假设的误差概率:
对于假设空间中的所有假设,出现泛化误差与经验误差之差大于e的概率和为:
因此,令不等式的右边小于(等于)
VC维
现实中的学习任务通常都是无限假设空间,例如d维实数域空间中所有的超平面等,因此要对此种情形进行可学习研究,需要度量假设空间的复杂度。这便是VC维(Vapnik-Chervonenkis dimension)的来源。在介绍VC维之前,需要引入两个概念:
- 增长函数:对于给定数据集D,假设空间中的每个假设都能对数据集的样本赋予标记,因此一个假设对应着一种打标结果,不同假设对D的打标结果可能是相同的,也可能是不同的。随着样本数量m的增大,假设空间对样本集D的打标结果也会增多,增长函数则表示假设空间对m个样本的数据集D打标的最大可能结果数,因此增长函数描述了假设空间的表示能力与复杂度。
对于不同的数据集,增长函数可能不相同。
- 打散:例如对二分类问题来说,m个样本最多有2^m个可能结果,每种可能结果称为一种**“对分”**,若假设空间能实现数据集D的所有对分,则称数据集能被该假设空间打散。
因此尽管假设空间是无限的,但它对特定数据集打标的不同结果数是有限的,假设空间的VC维正是它能打散的最大数据集大小。通常这样来计算假设空间的VC维:若存在大小为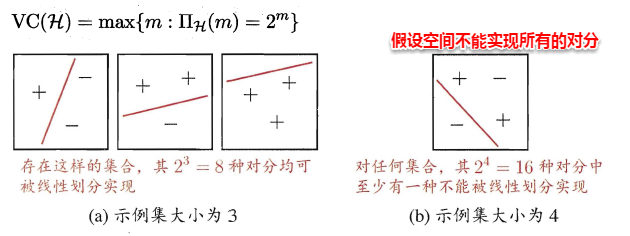
同时书中给出了假设空间VC维与增长函数的两个关系:
直观来理解(1)式也十分容易: 首先假设空间的VC维是
在有限假设空间中,根据Hoeffding不等式便可以推导得出学习算法的泛化误差界;但在无限假设空间中,由于假设空间的大小无法计算,只能通过增长函数来描述其复杂度,因此无限假设空间中的泛化误差界需要引入增长函数。
定理12.2 对假设空间
和任意 ,有 代入定理便可得无限假设空间的泛化误差界:
上界(多余此数目则可学到):
下界(少于此数目则可学到):
上式给出了基于VC维的泛化误差界,同时也可以计算出满足条件需要的样本数(样本复杂度)。若学习算法满足经验风险最小化原则(ERM),即学习算法的输出假设
稳定性
稳定性考察的是当算法的输入发生变化时,输出是否会随之发生较大的变化,输入的数据集
表示移除 中第 个样例得到的集合: ; 表示替换 中第 个样例得到的集合: ,其中 , 服从分布 并独立于 。
若对数据集中的任何样本
其中
事实上,若学习算法符合经验风险最小化原则(ERM)且满足β-均匀稳定性,则假设空间是可学习的。稳定性通过损失函数与假设空间的可学习联系在了一起,区别在于:假设空间关注的是经验误差与泛化误差,需要考虑到所有可能的假设;而稳定性只关注当前的输出假设。